

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
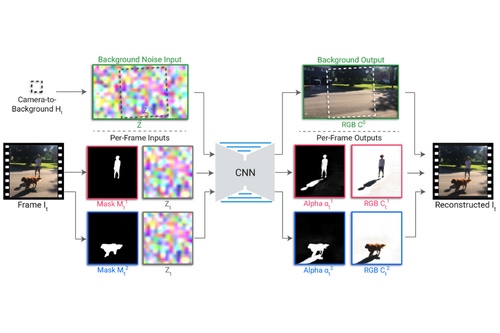
The model is trained to reconstruct input footage as a composition of each layer, and then predict the RGBA color value for each segmentation mask
Google researchers have unveiled Omnimattes: a new model-based method of removing objects like shadows from videos.
Forrester Cole, a Google software engineer, and research scientist colleague Tali Dekel published a nine-page paper outlining the process.
The pair suggested that their matting method can isolate and extract partially transparent effects in scenes – like tire smoke or reflections, by predicting a mask of an object and its effects using correlations between it and its environment.
“Our solution is to apply our previously developed layered neural rendering approach to train a convolutional neural network (CNN) to map the subject’s segmentation mask and a background noise image into an Omnimatte,” the paper reads.
“Due to their structure, CNNs are naturally inclined to learn correlations between image effects, and the stronger the correlation between the effects, the easier for the CNN to learn. The CNN learns the stronger correlations first, leading to the correct decomposition.”
In image processing, a matte defines the different foreground or background areas of an image. Matte Generation helps refine transparent areas of a video or image.
The idea of an Omnimatte is effectively a matte for each object and its effects in a scene.
Cole and Dekel, who penned the paper, developed the Omnimatte system in collaboration with Erika Lu, a University of Oxford Ph.D. student during two internships at Google.
Google researchers Michael Rubinstein, William Freeman, and David Salesin were also involved in its development, as were University of Oxford researchers Weidi Xie and Andrew Zisserman.
The model they created is trained per video to reconstruct footage by using a composition of layers for each foreground object, and one layer for the background. The model that Omnimatte creation utilizes is trained via self-supervised training - a method of training neural networks that relies only on the input data.
For each input video, the model is trained to reconstruct the footage as a composition of each layer. The model then predicts the RGBA color value for each segmentation mask along with a background.

The above example Google showed off sees a segmentation network, in this case, MaskRCNN, which takes an input video (left) and produces plausible masks for people and animals (middle) but misses their associated effects. The method developed by Google’s research team produces mattes that include not only the subjects, but their shadows as well (right; individual channels for person and dog visualized as blue and green).
The model could potentially be used by visual effects team without the need to add any manual labels to footage.

Demonstrating the Omnimattes process, footage of a car drifting saw the system picking up the smoke it produces, as well as dogs walking – which are then placed in separate layers to ones with their owners.
Omnimattes can also be used to show background replacement - where the original shadow remains, as well as a stroboscope effect that shows multiple versions of the same object across time.
The paper Cole and Dekel penned “is a great example of the extra resources that can be released alongside [Omnimattes] to help the reader understand the impact and usefulness of the findings,” said Scott Condron, a machine learning engineer at Weights & Biases.
While the system only supports backgrounds that can be modeled as panoramas from a fixed camera at present, Dekel and Cole said it could be improved upon in the future.
Should the camera position move, the model cannot accurately capture the entire background, with some background elements potentially clutter up the foreground layers.
“Handling fully general camera motion, such as walking through a room or down a street, would require a 3D background model. Reconstruction of 3D scenes in the presence of moving objects and effects is still a difficult research challenge, but one that has seen promising recent progress,” they wrote in a blog post.
“While our system allows for manual editing when the automatic result is imperfect, a better solution would be to fully understand the capabilities and limitations of CNNs to learn image correlations. Such an understanding could lead to improved denoising, inpainting, and many other video editing applications besides layer decomposition.”
The Omnimattes source code can be found on GitHub and is available under a Apache 2.0 license.
You May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)