

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Researchers came up with method for fine-tuning AI models for language learning.

Google has unveiled an expansion to its Universal Speech Model (USM), saying it now supports over 300 languages.
The USM is part of Google’s pledge made last November to build a machine learning model that encompasses as many languages as possible. Most main models like OpenAI’s ChatGPT offer limited language support outside of English.
In a blog post announcing the milestone, Google Research scientist Yu Zhang and software engineer James Qin said USM now boasts two billion parameters and has been trained on 12 million hours of speech and 28 billion sentences of text.
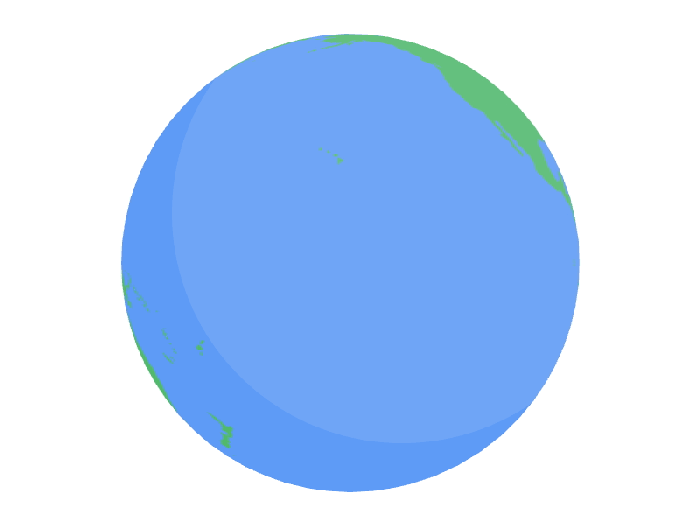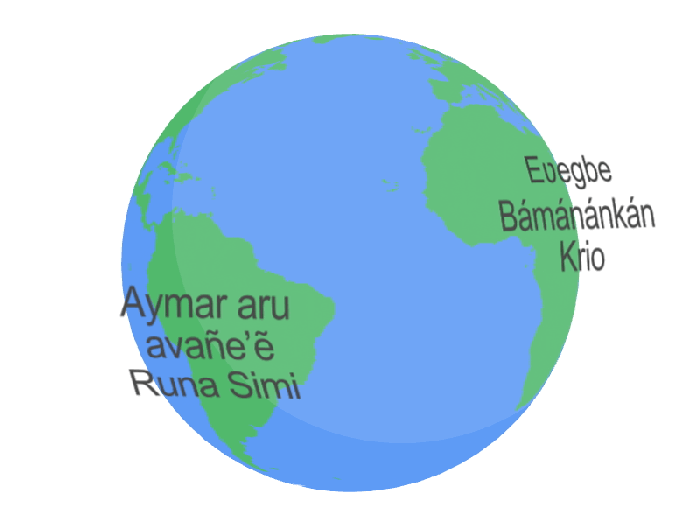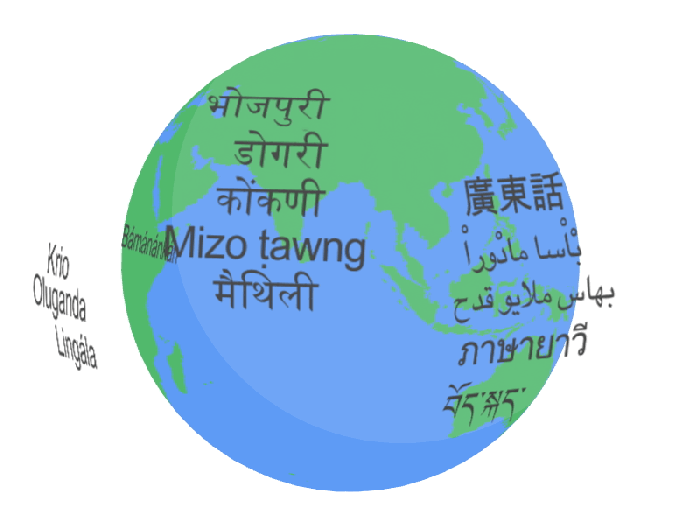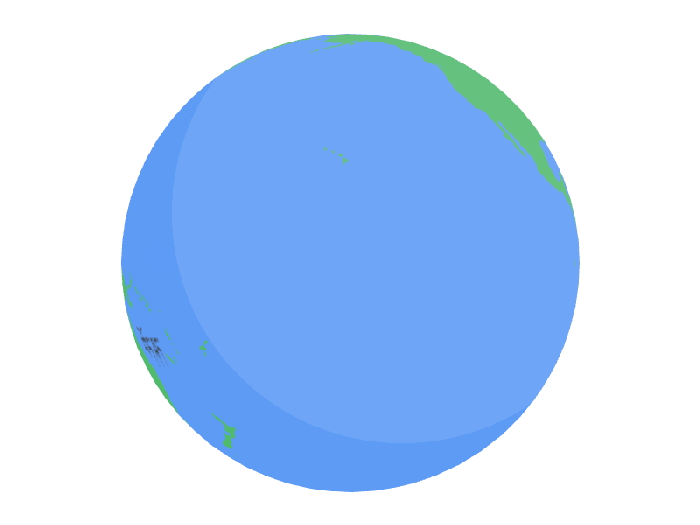
Google's ultimate goal for USM is for it to work across 1,000 languages – a mammoth task, but one its researchers contend is achievable based on the success of its recent work.
Using a standard encoder-decoder architecture, USM uses a Conformer, or convolution-augmented transformer, which takes the log-mel spectrogram of speech signals as input and performs a convolutional sub-sampling. Then, a series of Conformer blocks and a projection layer are applied to obtain the final embeddings.
In simpler terms, The Google researchers achieved the 300 language milestone by using a large unlabeled multilingual dataset to pre-train the encoder of the model and then fine-tuned it on a smaller set of labeled data.
The research team said that this approach was more effective at adapting an ML model for new languages than prior techniques.
The model is already being used by Google’s YouTube platform to generate closed captions for “under-resourced” languages like Amharic, Cebuano, Assamese and Azerbaijani, among others. The model achieves less than a 30% word error rate on YouTube on average across 73 languages.
The researchers tout that in its current form, USM has a relatively lower word error rate than OpenAI’s Whisper model for some 18 languages.
However, to achieve its lofty goal of 1,000 languages, Zhang and Qin note that computational efficiency needs to be improved to expand both language coverage and quality.
“This requires the learning algorithm to be flexible, efficient, and generalizable. More specifically, such an algorithm should be able to use large amounts of data from a variety of sources, enable model updates without requiring complete retraining, and generalize to new languages and use cases,” the post reads.
You May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

