Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Getting models trained in Python to run in embedded C++ can be a challenge, but a new generation of tools is making it simple.
April 12, 2023
Sponsored Content
The past few years have seen an explosion in the use of artificial intelligence on embedded and edge devices. Starting with the keyword spotting models that wake up the digital assistants built into every modern cellphone, “edge AI” products have made major inroads into our homes, wearable devices, and industrial settings. They represent the application of machine learning to a new computational context.
ML practitioners are the champions at building datasets, experimenting with different model architectures, and building best-in-class models. ML experts also understand the potential of machine learning to transform the way that humans and technology work together. For this reason, they are often the experts tasked with figuring out how to solve problems on the edge.
While today’s ML engineers are often competent across a range of parallel disciplines, from software engineering to cloud computing, it’s rare for ML practitioners to have direct experience with embedded systems. There’s not a lot of overlap between the high-level skills required for working with data and the low-level skills required to build efficient embedded software that is coupled tightly to the processor where it runs.
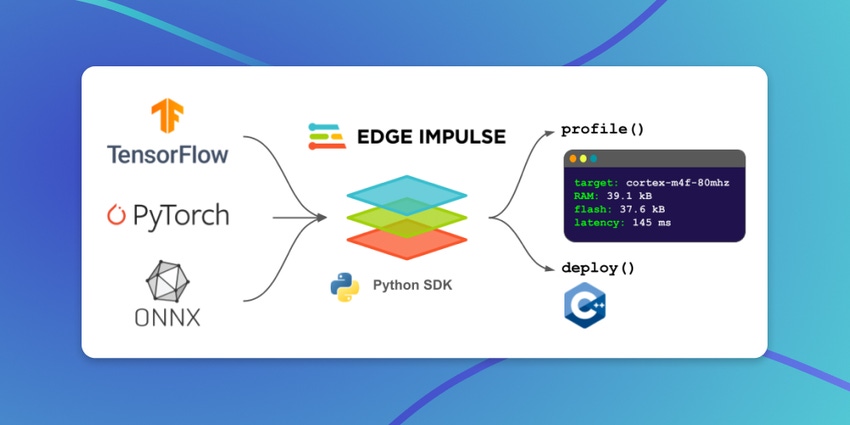
One major challenge is the task of taking a deep learning model, typically trained in a Python environment such as TensorFlow or PyTorch, and enabling it to run on an embedded system. Traditional deep learning frameworks are designed for high performance on large, capable machines (often entire networks of them), and not so much for running efficient inference on the types of processors used in today’s embedded systems. It’s common to have only tens or hundreds of kilobytes of ROM available to store model weights and runtime code, or RAM for intermediate activations during inference.
While a few DIY solutions exist for porting models to embedded systems, they’re typically complex, difficult to use, lacking in support for the vast array of unique embedded processors that exist, and make use of tools that are unfamiliar to ML practitioners. While embedded engineers are extremely capable with embedded toolchains, they’re unlikely to have the expertise required to assist with porting deep learning models.
Fortunately, a new generation of tools is assisting both ML practitioners and embedded engineers to bridge the gap between model training and embedded deployment. Designed to integrate directly with Python’s massive ecosystem of data science and machine learning tools, tools like Edge Impulse’s "Bring Your Own Model” can convert a trained deep learning model into an optimized C++ library that is ready to integrate into any embedded application.
There are two key functions necessary to help ML practitioners feel productive when developing models for embedded targets. They are:
Model profiling: It should be possible to understand how a given model will perform on a target device—without spending huge amounts of time converting it to C++, deploying it, and testing it. Developers need to know RAM and ROM usage and be able to estimate the latency of the model on the target, or how long it will take to perform a single inference. This information is essential to guiding the development of a suitable model architecture. It’s important that the
Model optimization and C++ conversion: It needs to be possible to take a model and rapidly convert it into portable C++ code that can be tested on embedded targets. This process should include applying optimizations, such as quantization, that are essential to achieving good performance on embedded targets. The generated code needs to be optimized to perform well on the processors that are being targeted.
Automating these functions enables teams to be far more productive. For example, an embedded engineer can feel empowered to take the latest model produced by the ML team and convert it into efficient C++, and an ML engineer can confidently factor in on-device performance without having to become familiar with a complex and finicky embedded toolchain.
The biggest win from this approach comes from tightening the feedback loop between model development and testing on-device. When the process takes seconds instead of hours, and can be self-served rather than depending on inter-team communication, development can proceed at a much faster rate, reducing costs, risks, and overall stress. Tricky decisions, such as deciding the embedded processor to select for a particular project, or whether a model should be made larger or smaller, can be made using a data-driven approach rather than guesswork.
It’s important that the tooling integrates well with other parts of the ML ecosystem. For example, a Python model profiling tool should accept popular model formats as input—such as those used by TensorFlow and PyTorch, or provided by platforms like Hugging Face.
MLOps is an important part of the modern ML workflow, and any tooling should output results in a form that can be integrated into MLOps solutions. For example, you should be able to upload on-device latency estimates into an experiment tracker like Weights and Biases during a hyperparameter sweep.
At Edge Impulse, our ML team has built out a set of tools that solve the problems outlined above. As a working embedded machine learning team, we built these tools to solve the types of problems we’ve personally experienced while collaborating with embedded engineers.
Our experience so far has been fantastic. We’ve found it shocking how much our productivity working alongside embedded teams has increased after streamlining our profiling and deployment workflow. It’s suddenly a trivial question to determine whether a model will fit on a given target, or to provide ready-to-go code for engineers to evaluate.
The tools we’ve built are now available to developers, under the name Bring Your Own Model (BYOM). The BYOM features can be accessed via either Python SDK or a web interface, depending on what you prefer. You can use these tools to estimate latency and memory use, convert models to C++, and even quantize models from float32 to int8 representation.
Model conversion and deployment has traditionally been one of the most challenging aspects of working with edge AI. Many teams have had nasty surprises when they discover that the models they’ve spent months developing are not a good fit for the hardware they must deploy to.
Fortunately, recent advances in tooling mean that practitioners can spend minimal time wrestling with C++—and more time on creating the high quality datasets and efficient models required for edge AI.
Brought to you by:
![]()
You May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)


.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)