.png?width=100&auto=webp&quality=80&disable=upscale "Picture of Stephen Bolinger")
.png?width=400&auto=webp&quality=80&disable=upscale "Stephen Bolinger")
Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
An opinion piece from Stephen Bolinger, chief privacy officer of Informa, the parent of AI Business
.jpg?width=850&auto=webp&quality=95&format=jpg&disable=upscale)
Most people have now heard of ChatGPT, a generative AI large language model released by OpenAI in November 2022. The service is currently in a ‘free research preview’ for anyone to try and is now also available to commercial subscribers via an API, with commercial integrations announced by Snap, Salesforce-owned Slack and a variety of Microsoft products and services (following Microsoft’s multi-billion dollar investment in OpenAI), to name a few. ChatGPT allows users to submit typed “prompts” (e.g. questions, beginnings of stories to continue, etc.), then outputs text that reads as convincingly human and confidently authoritative.
While this new technology is exciting, there are risks with using it, such as inputting sensitive personal or business information which may be retained or reused by the service. ChatGPT has also been known to make errors, both factually and in 'judgment.' This, of course, affects how we should approach using ChatGPT in its formative stages.
In many respects, ChatGPT is a technological marvel. A lawyer asks it for a summary of a law, a communications professional asks it to polish up a press release, programmers ask it to write code and a student asks it to draft a three-page essay on how the political activities at the end of WWI stoked the tensions that led to WWII.
It has so many uses, for so many people, which is why it reached over one million users in the first five days of its public availability and 100 million users after just two months. For comparison, attaining 1 million users took Facebook 10 months, Spotify five months and Instagram 2.5 months.
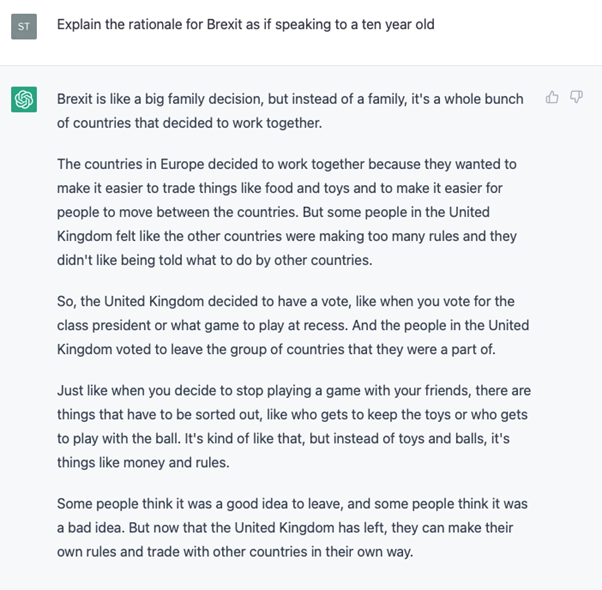
Here's an example of ChatGPT attempting to explain the U.K.’s departure from the EU to a child:
ChatGPT sits within a broad AI category called generative AI, which creates content through AI models that are trained on vast sets of data. Other generative AI tools can create realistic human voices, imagery and even video with entirely synthetic (but realistic) human actors.
In ChatGPT’s case, its model was trained on over eight million documents and over 10 billion words, largely collected from the publicly available internet. The vast size of ChatGPT’s training data is central to its capability but sourcing it from the open internet is its Achilles’ heel.
In contrast with ChatGPT’s amazing abilities, it has some concerning flaws, the most prominent and prevalent being that it is often wrong. There have been examples of it confidently describing living people as dead, miscalculating basic math, constructing racist content and regurgitating conspiracy theories as news.
Google’s answer to ChatGPT, Bard, made an embarrassing public mistake in its unveiling demo, stating that the James Webb Space Telescope (JWST) “took the very first pictures of a planet outside of our own solar system.” That honor went to the European Southern Observatory's Very Large Telescope (VLT) in 2004 — many years before the JWST even existed.
Despite the valid concerns expressed by some over the erroneous and harmful responses from ChatGPT, the accuracy and overall quality of the content produced by ChatGPT and its rivals will undoubtedly improve over time. As Bill Gates recently pointed out in a conversation with the FT’s Gideon Rachman, many of the examples of ChatGPT’s failures are a direct result of individuals intentionally trying to trip it up rather than any inherent malevolence within the tool itself. Nonetheless, improved training and technical guardrails should likely lessen the likelihood of harmful outputs as this category of tools evolves.
One important fact-checking capability is being able to identify the sources large language models like ChatGPT have relied on to produce their answers. An example of this is seen in Microsoft’s new Bing chat feature based on the underlying ChatGPT technology, currently in preview.
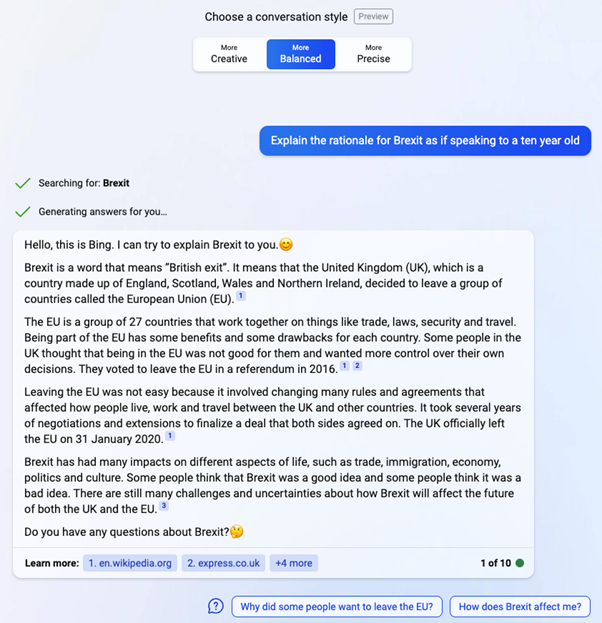
Above you see the same question submitted to Bing, but Microsoft has added a conversation style control at the top (from ‘creative’ to ‘precise’) and, importantly, links to websites that correlate with the specific statements in its answer. This should help users to fact-check and consider the trustworthiness of the source content.
Nonetheless, until substantial improvements are made, these tools should be avoided for answers that must be factually correct, unless individuals rigorously fact-check the answers via trusted sources.
Beyond the issues of accuracy and quality, organizations should have serious concerns over how data provided to ChatGPT may be retained and used. In particular, OpenAI’s Frequently Asked Questions on ChatGPT specifically confirms that conversations will be used for further training of the model.
OpenAI has recently updated its terms of service for the paid version of its ChatGPT API to commit not to use data submitted through the API for service improvements (including model training) without the consent of the commercial subscriber.
Given the retention and ongoing use of conversation data received through the free ChatGPT service, individuals and organizations should avoid including any personal or confidential information in their prompts (e.g. asking it to draft an employee warning letter, submitting a confidential business plan for it to rewrite, or asking for advice in treating a medical condition). Doing so could raise the risk of the information being disclosed should ChatGPT suffer a breach or even result in ChatGPT incorporating information into the answers it provides back to others.
For more information on some of the specific privacy risks related to ChatGPT see this article from leading privacy and technology lawyer, Mike Hintze. For those who want to learn a bit more about how ChatGPT (and large language models, generally) work, check out ChatGPT Explained: A Normie’s Guide to How It Works by Jon Stokes.
By all means, check out ChatGPT if you haven’t already. Ask it for a biography of someone you admire told as a rap in the style of Eminem. Ask it to make up a story for your kids that includes their favorite things but includes the lesson that it's important to go to bed early. Ask it to explain in simple terms a difficult concept you’ve always wanted to know more about.
I expect this class of tools to eventually become so commonplace in helping us through simple (and perhaps even complex) tasks that their internal functioning will be as uninteresting as a word-processing program to most people. But for now, be sure not to share personal information or your company’s confidential information with it and be prepared to do a bit of fact-checking for any responses you intend to rely upon.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)