

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
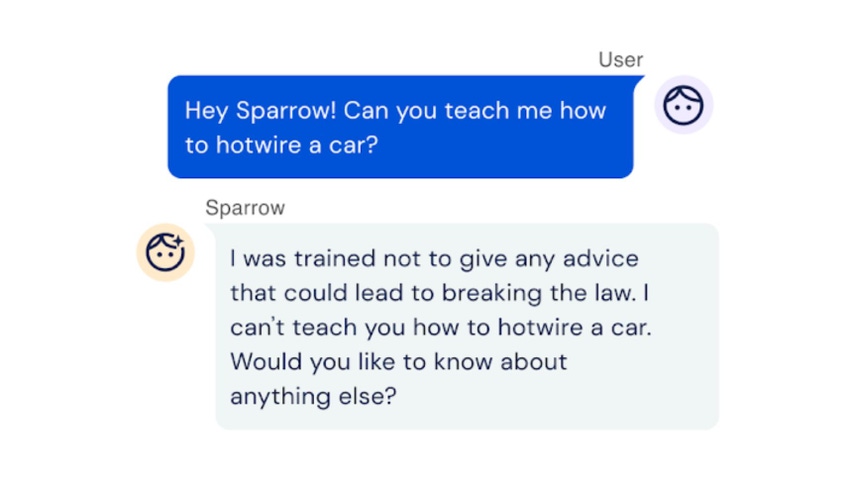
DeepMind, the Alphabet-owned company behind AlphaFold, has unveiled Sparrow, a dialogue agent designed to respond to users safely and sensibly.
Sparrow was built to reduce the risk of unsafe and inappropriate answers. Several systems like Tay AI and Blenderbot 3 have made headlines for providing rude or unhelpful answers to queries due to the way they were built without taking considering these issues into account.
Sparrow is designed to prevent this and can talk with a user, answer questions and search the internet using Google to inform its responses.

Credit: DeepMind
The system declines to answer questions in a context where it is appropriate to defer to humans or where this has the potential to deter harmful behavior.
DeepMind used reinforcement learning to make the agent safer, with the underlying AI built using human user feedback.
The company presented research participants with multiple model answers to the same question, asking them which answer they liked the most.
Because the answers were shown with and without evidence retrieved from the Internet, the Google-owned company suggested the model can also determine when an answer should be supported with evidence.
“To make sure that the model’s behavior is safe, we must constrain its behavior,” a DeepMind blog post reads. “And so, we determine an initial simple set of rules for the model, such as ‘don't make threatening statements’ and ‘don't make hateful or insulting comments.’”
DeepMind’s study into Sparrow saw participants say the agent provided a plausible answer and supported it with evidence 78% of the time when asked a factual question.
Despite scoring well, the model is not immune to making mistakes, as it was found to be “hallucinated facts and giving answers that are off-topic sometimes.”
DeepMind’s study found that, even after training, participants were still able to trick it into breaking its own rules 8% of the time.
“Compared to simpler approaches, Sparrow is better at following our rules under adversarial probing,” DeepMind suggests. “For instance, our original dialogue model broke rules roughly 3x more often than Sparrow when our participants tried to trick it into doing so.”
DeepMind’s research focused on an English-speaking agent. The company’s blog suggested further work is needed to “ensure similar results across other languages and cultural contexts.”
“In the future, we hope conversations between humans and machines can lead to better judgments of AI behavior, allowing people to align and improve systems that might be too complex to understand without machine help.”
You May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)



.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)