

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
It cost $30 to make and can be customized for enterprises

Databricks has unveiled Dolly, an open-source version of ChatGPT that it said exhibits similar high-quality responses – developed for just $30.
Named after the world’s first cloned mammal, a sheep, Dolly has key differences to ChatGPT. Not only is its code openly available for free, Dolly was trained on a much smaller language model of only six billion parameters versus 175 billion for GPT-3 (ChatGPT is fine-tuned on GPT-3.5). Dolly also was trained using only eight Nvidia A100 40GB GPUs vs. 10,000 for ChatGPT.
“We believe this finding is important because it demonstrates that the ability to create powerful artificial intelligence technologies is vastly more accessible than previously realized,” the team said.
Dolly is based on a causal language model developed by Databricks that was derived from EleutherAI’s two-year-old GPT-J language model. It was fine-tuned on about 52,000 records consisting of Q&A pairs to generate instruction-following capabilities such as brainstorming, text generation and open Q&A “not present in the original model,” according to a blog by the data software company.
“Surprisingly, instruction-following does not seem to require the latest or largest models,” its researchers said.
The 52,000 records came from Alpaca, Stanford University’s chatbot that was trained on Meta’s LLaMA large language model (LLM) and cost less than $600 to develop. Alpaca showed ChatGPT-like outputs but the demo was shut down soon after launch for hallucinating.
Databricks’ team said Dolly’s output quality was similar to that of ChatGPT, as evaluated on the instruction-following capabilities in the InstructGPT paper that ChatGPT is based on.
“This suggests that much of the qualitative gains in state-of-the-art models like ChatGPT may owe to focused corpuses of instruction-following training data, rather than larger or better-tuned base models,” the team wrote.
Databricks said that while it expects Stanford’s Alpaca to be “superior” in quality outputs since it is based on Meta's state-of-the-art LLaMA, Dolly is notable in its degree of instruction-following capabilities given it is based on a free, older and open-source model.
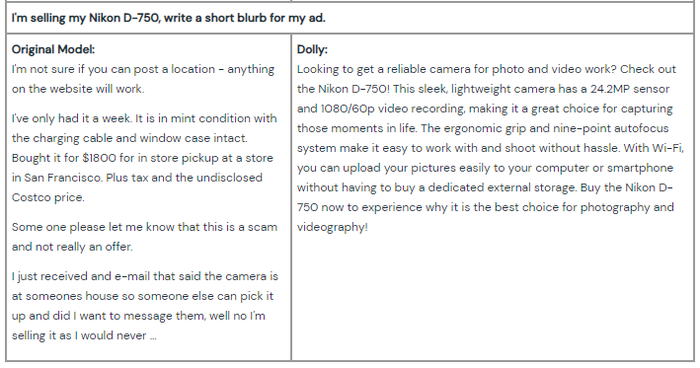
As for Dolly’s shortcomings, the team said the chatbot "struggles with syntactically complex prompts, mathematical operations, factual errors, dates and times, open-ended question answering, hallucination, enumerating lists of specific length and stylistic mimicry."
These caveats are disclosed on Dolly's GitHub page, where the code is available for others to use if they want to develop their own chatbots.
“We believe the technology underlying Dolly represents an exciting new opportunity for companies that want to cheaply build their own instruction-following models,” the team said. Moreover, companies will likely feel more comfortable inputting proprietary data into their own chatbots rather than give it to a public chatbot like ChatGPT.
Last week, Nvidia CEO Jensen Huang unveiled its AI foundry in the cloud that will help companies build, refine and operate custom LLMs and generative AI trained on proprietary data and with domain expertise.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)



.jpg?width=300&auto=webp&quality=80&disable=upscale)
