

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
The model can generate audio in six languages from just a 2-second sample

AI researchers at Facebook parent Meta have unveiled Voicebox, an AI model that can generate speech in different styles using an audio sample that’s just two seconds long.
Using a new approach, Voicebox learns from both raw audio and an accompanying transcription. Prior generative AI speech models required specific training for each task using carefully prepared training data.
Voicebox can match the style for text-to-speech generation and can also be used to edit audio – such as removing background noises of a dog barking or distant car horns. The editing process works by recreating a portion of the speech that's interrupted by noise without having to re-record an entire speech.
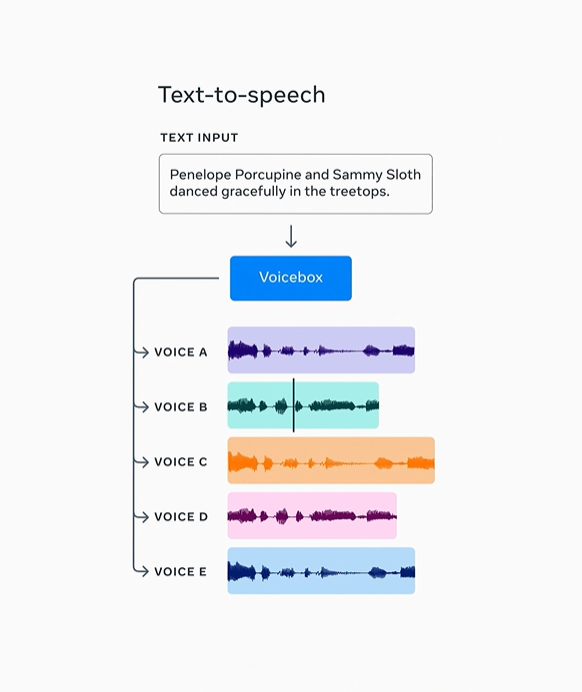
Image: Meta
The model is also multilingual and can produce speech in six languages – English, French, German, Spanish, Polish and Portuguese. Voicebox can produce a version of the text in different languages, even when the sample speech and the text are in different languages.
Meta CEO Mark Zuckerberg demoed the model in a video on the company's research blog, saying his team believes Voicebox is “the most versatile speech generative model out there.”
“This is still a research project, but I think we’re going to build a lot of interesting things with tools like this,” said Zuckerberg.
Stay updated. Subscribe to the AI Business newsletter
Voicebox is designed to be multipurpose – or used for a variety of tasks – something Meta has been pushing for its AI models so that they can be applied to a variety of use cases and applications.
Meta said that in the future, multipurpose generative models like Voicebox could “give natural-sounding voices to virtual assistants and non-player-characters in the metaverse.”
“They could allow visually impaired people to hear written messages from friends read by AI in their voices, give creators new tools to easily create and edit audio tracks for videos, and much more,” the research team behind it said.
Meta is not making the model public, however, over fears of potential misuse. “While we believe it is important to be open with the AI community and to share our research to advance the state of the art in AI, it’s also necessary to strike the right balance between openness with responsibility,” Meta said.
Instead of publishing codes or the model itself, Meta has shared audio samples and a research paper detailing the approach and results.
Earlier this month, U.S. lawmakers sent a letter to Zuckerberg saying they were concerned about the release of Meta’s LLaMA given the power of this large language model.
“We are writing to request information on how your company assessed the risk of releasing LLaMA, what steps were taken to prevent the abuse of the model, and how you are updating your policies and practices based on its unrestrained availability,” wrote Sen. Richard Blumenthal (D-CT), chair of the Senate Subcommittee on Privacy, Technology & the Law, and Josh Hawley (R-MO), ranking member.
They added that “even in the short time that generative AI tools have been available to the public, they have been dangerously abused – a risk that is further exacerbated with open source models.”
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)