

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Vector databases are particularly useful to large language models

While working at a tech startup in Germany, André Zayarni and Andrey Vasnetsov wanted to create a solution to optimize search in unstructured HR data. But there was not a tool to help with this complex process. So Zayarni and Vasnetsov set out to build their own. They used the Rust language to create a vector database and open sourced it in May 2021.
“We received a lot of positive feedback from the community,” said Zayarni. “We decided to go full into this.”
Growth at their startup, Qdrant, would later accelerate because of the interest in generative AI. This led to a $28 million round of funding in January. “We had two lead term sheets in parallel,” said Zayarni. “There were also dozens of co-investment inquiries and an acquisition request.”
Other vector database startups have also gained the attention of top investors, such as Pinecone. Last year, it announced a $100 million round at a $750 million valuation. The lead investor was Andreessen Horowitz.
With surging demand for generative AI, vector databases are rising in popularity. This technology lets enterprise apps effectively search large amounts of unstructured data, helping to reduce hallucinations and greatly improve the responses of LLMs.
“The specialized vector database and existing databases now implementing vector capabilities are fundamentally changing the way organizations are using databases,” said Andi Gutmans, who is the general manager and vice president for databases at Google Cloud.
“This follows the industry’s history of once-edge case innovations being incorporated into the mainstream, but this time it is one of several new capabilities and performance improvements designed to bridge between LLMs and enterprise apps in a more seamless manner.”
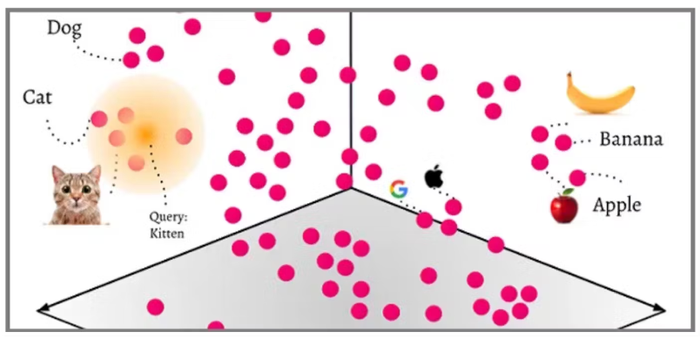
A vector database specializes in storing unstructured data such as text, images or audio that are converted into numerical embeddings. These embeddings are large arrays of numbers across multiple dimensions that can be efficiently searched, processed and analyzed. This transformation is critical for feeding sophisticated deep learning models.
Vector databases can handle large datasets. They also allow for sophisticated searching and comparison of data - looking for similar data (cat, kitten) rather than exact data (just cat), which speeds up the process. When combined with techniques like Retrieval Augmented Generation (RAG), vector databases can reduce “hallucinations,” which is when LLMs generate irrelevant or nonsensical information.
Credit: MongoDB
“Vector databases are purpose-built for similarity searches and have a very simple data model where unstructured data is indexed by a vector and query patterns based on a small set of similarity algorithms,” said Sudhir Hasbe, who is the chief product officer of Neo4j. “This makes it very simple for developers to ingest their data and initiate their projects.”
A use case is Bloomberg’s new application to generate summaries of corporate earnings calls. It extracts insights about guidance, capital allocation, hiring, new products and the macro environment.
"Our solution uses a large language model and a combination of dense and sparse vector indices for semantic matching, along with pre- and post-processing,” said Anju Kambadur, who is the head of AI engineering at Bloomberg. “Each summary is linked to its corresponding source content in the original call transcript to enhance transparency.”
Or consider SkyPoint, which is a provider of end-to-end enterprise AI solutions. By using DataStax’s vector search capabilities in Astra DB, the company was able to develop a user-friendly chatbot for senior citizens in long-term care facilities. It allows them to interact with medical providers and caregivers.
“Residents are comforted, knowing that they can ask questions about how a new medication will interact with an existing medication and are sure that they will get an immediate, relevant response,” said Bill McLane, who is the CTO of cloud at DataStax.
There are a growing number of vector databases coming on to the market. Traditional relational database providers, whose software is designed to store structured data like those in spreadsheets, have also been implementing vector databases. Because of this, it is challenging to evaluate the best solution.
“Some vector databases are better for things like understanding language, while others are good for recognizing images or making suggestions,” said Lucas Ochoa, who is the CEO and founder of Automat. “Other considerations are your app’s speed requirements as well as if it works online or in an offline batch mode. Also, do you have a team to host a system? If not, a managed vector database might be a better option.”
It is important to keep in mind the difference between vector databases and vector search. A vector database is built for narrow use cases. But if you have broader requirements, you might want a more extensive database solution.
“A drawback of a vector database as a point solution is that it can introduce complexity into the broader architecture,” said Scott Anderson, who is the senior vice president of product management and business operations at Couchbase. “When it comes to AI, each new and different database that is introduced becomes a risk point. Having multiple database point solutions makes it very hard to find out where debugging is needed if the AI application is hallucinating and returning inaccurate or irrelevant results.”
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)