

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Meta's V-JEPA AI redefines video analysis, mimicking human perception

The preference of Meta’s Yann LeCun for non-generative AI models took another step forward today, with the unveiling of the latest version of its JEPA model.
Meta’s chief AI scientist has long favored Joint-Embedding Predictive Architectures, or JEPA - which predicts missing information rather than merely text - over generative AI. Its first model, I-JEPA, learns by creating an internal model of the outside world. This is closer to how humans learn; typically machines need thousands of examples and hours of training to learn a single concept, according to Meta.
Now, the research team he leads has published its second JEPA model which is focused on video.
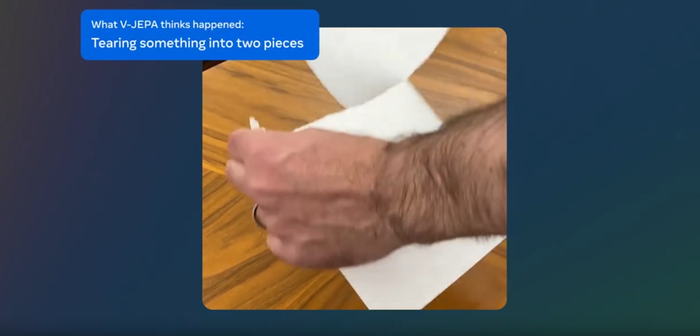
Dubbed V-JEPA, the model predicts missing or masked parts of a video in an abstract representation space.
Meta said the model learns like an infant, in that it can watch passively to understand the context and then acquire the skills shown. V-JEPA was not trained to understand specifics. Instead, it uses self-supervised training to watch and understand a range of videos.
V-JEPA could be used to improve machines’ abilities to understand the world around them by watching videos, with LeCun saying it could help them “achieve more generalized reasoning and planning.”
“Our goal is to build advanced machine intelligence that can learn more like humans do, forming internal models of the world around them to learn, adapt, and forge plans efficiently in the service of completing complex tasks,” he said.
Credit: Meta
The system is pre-trained entirely with unlabeled data. Unlike generative models that try to fill in every missing pixel, V-JEPA can discard unpredictable information, which Meta contends leads to improved training and sample efficiency by a factor of 1.5 to six times.
So far, the model can handle visual but not audio content. Meta said it is thinking about incorporating audio along with the visuals.
Also, it is just a research model at present – so do not expect to use it in your computer vision systems any time soon. But Meta said it is “exploring a number of future applications.”
“We expect that the context V-JEPA provides could be useful for our embodied AI work as well as our work to build a contextual AI assistant for future AR glasses.”
You can access it on GitHub, however, for research purposes. It is available under a Creative Commons Noncommercial license with Meta wanting researchers to “extend” their work.
Meta had been fairly quiet on JEPA work since it released I-JEPA last June, with LeCun only revealing that a version focusing on video was in development at the World AI Cannes Festival last week.
LeCun’s dislike for generative systems – and the wider machine learning landscape at present - is that they lack an understanding of how the world works − as well as the ability to remember, reason and plan.
When speaking about I-JEPA at Cannes last week, LeCun said the model had not been trained on a big dataset but “seems to overpower” Meta’s DINOv2 computer vision model.
You May Also Like


.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)