

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
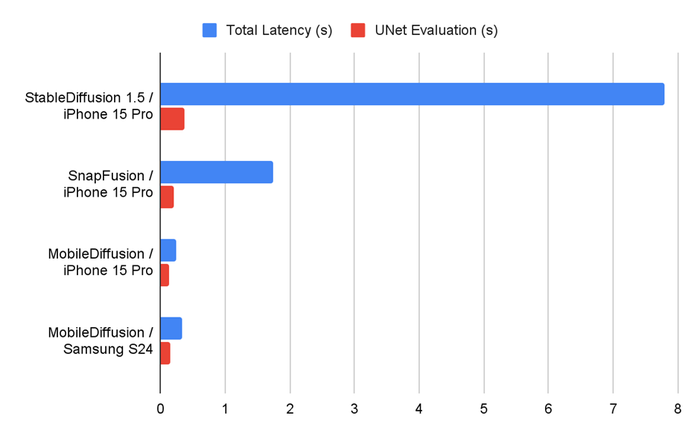
The small model fits on mobile devices meant for consumers, enabling half-a-second image generations

Google researchers have developed a text-to-image AI model that can produce high-quality images at the edge − on a mobile device.
The aptly named MobileDiffusion is a minuscule model that can create 512x512 images at rapid speeds because it does not have to go to the cloud for processing since it is on the device. The team behind the model assessed it on both iOS and Android devices and claimed it ran in half a second.

Credit: Google
Image generation models like Stable Diffusion and DALL-E are billions of parameters in size and require powerful desktops or servers to run, making them impossible to run on a handset.
Google researchers sought to change that and created a diffusion model specifically designed for mobile devices.
The result is a 520 million-parameter model that can create images from text prompts at speed with limited latency.
Credit: Google
Such a small model enables image generation models to work in mobile devices meant for consumers, widening access to AI image creation.
“With superior efficiency in terms of latency and size, MobileDiffusion has the potential to be a very friendly option for mobile deployments given its capability to enable a rapid image generation experience while typing text prompts,” Google’s researchers wrote in a blog post.
MobileDiffusion follows the design principles of latent diffusion models: It has a text encoder, a diffusion UNet and an image decoder.
The model was designed to focus on optimizing the underlying model architecture and sampling techniques to achieve sub-second inferencing speeds.
Its underlying architecture effectively reduces sampling steps to speed up image generation time.
Traditional text-to-image diffusion models use a transformer block like the ones found in Stable Diffusion’s UNet architecture. These contain several layers, including a self-attention layer, which is responsible for powering text comprehension.
Google’s researchers, however, contend that these multi-layered blocks “pose a significant efficiency challenge, given the computational expense of the attention operation.”
Instead, they followed the idea of the Google-designed UViT architecture, which places more transformer blocks at the bottleneck of the UNet.
The MobileDiffusion paper states that this design choice “is motivated by the fact that the attention computation is less resource-intensive at the bottleneck due to its lower dimensionality.”
In addition, the researchers optimized MobileDiffusion’s image decoder, making it lightweight by using a technique called variational autoencoder (VAE) to encode an RGB image into a smaller, 8-channel latent variable. The resulting lighter decoder reduced latency by nearly 50% while improving the quality of the model’s image output.
“With such a compact model, MobileDiffusion can generate high-quality diverse images for various domains,” according to the paper.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)