

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
The latest Google AI model can handle hefty multimodal files – but latency issues are expected upon initial launch

The AI race is heating up as Google unveiled the latest update to its powerful Gemini multimodal model – it boasts a staggering one million-token context window.
According to a Google blog post, Gemini 1.5 outperforms the initial version of Gemini and can handle up to one million multimodal tokens. That comes to around 700,000 words, one hour of video, 11 hours of audio or 30,000 lines of code at a time, according to Google. For comparison, OpenAI’s GPT 4 Turbo’s context window stands at just 128,000.
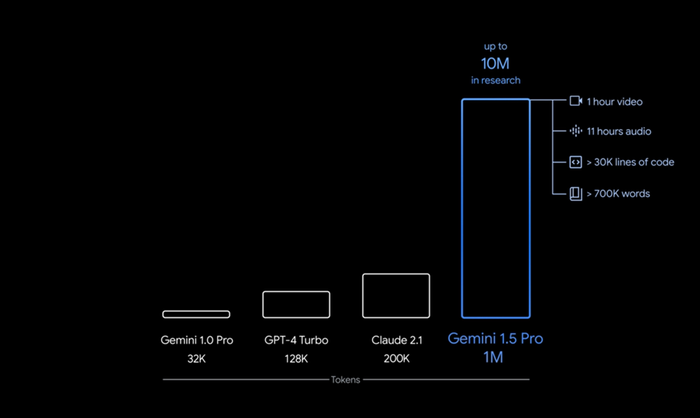
Credit: Google
The first version headed to users is Gemini 1.5 Pro, a mid-sized multimodal model. Developers and enterprise customers can try out the hefty context window via AI Studio and Vertex AI in a private preview. Google said Gemini 1.5 Pro is as powerful as Gemini 1.0 Ultra – the most powerful model in the Gemini family.
There is no cost to try the one million context window version. However, Google said users should expect longer latency times as it is still an experimental feature.
Google CEO Sundar Pichai said in the blog post that Gemini 1.5’s beefed-up context window will “enable entirely new capabilities and help developers build much more useful models and applications.”
Google demoed the 1.5 Pro’s ability to derive information from a 402-page PDF transcript of the Apollo 11 moon landings as well as a series of multimodal prompts. The model was able to cite near exact timecodes of when quotes were said and even pick out relevant quotes based on a prompt of a crude drawing.
The unveiling of Gemini 1.5 Pro comes a day after Nvidia overtook Google as the third most valuable company in the U.S., after Microsoft and Apple. At the close of trading on Wednesday, Nvidia was worth $1.81 trillion while Google parent Alphabet came in at $1.78 trillion.
But investors were not impressed. As of midday trading today, Google shares slid 3.3% to $143.88.
Despite its ability to handle huge swathes of input, Gemini 1.5 uses less computing power than the Gemini 1.0 Ultra.
However, Demis Hassabis, CEO of Google DeepMind, said Google is working on optimizations to improve latency before rolling out the full one million token version of the model.
The new model was built using a combination of Transformer and Mixture of Experts (MoE) architecture – meaning it is made up of one large neural network as well as a series of smaller "expert” neural networks.
Hassabis said that the innovative architecture allows Gemini 1.5 to learn complex tasks more quickly and maintain quality while being more efficient in training. The new model “represents a step change in our approach, building upon research and engineering innovations across nearly every part of our foundation model development and infrastructure,” he said.
Omdia Chief Analyst Lian Jye Su said the model’s differentiated approach is a harbinger of what’s to come. “A mixture of Transformer and MoE architecture points towards a future with different AI training and inference approaches, especially when smaller expert models potentially require fewer training resources.”
Alexander Harrowell, Omdia principal analyst in advanced computing for AI, said the new architecture “confirms that Mixture of Experts is now the research frontier across AI, what with GPT-4, Mixtral, and now this. Google has a long-standing research focus on large MoE models, back to at least 2017, and invented the idea of combining the Transformer architecture and the mixture-of-experts principle.”
He pointed out that Google called Gemini 1.5 a mid-sized model but did not disclose the number of parameters for Gemini 1.5 or how many experts are in the MoE. However, “this seems to confirm that again, mid-size is the place to be,” Harrowell added.
Su noted that the timing of Gemini 1.5’s unveiling comes after OpenAI CEO Sam Altman teased the upcoming GPT-5’s improved capabilities “It shows that Google’s R&D to commercialization and productization cycle is catching up to OpenAI’s, though more benchmarks are required to make further comments about its performance.”
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)