

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
AI model sifts through 5,521 music examples to generate clips

Google researchers have unveiled MusicLM, an AI model that can generate high-fidelity music from text inputs.
Users can type in a prompt such as "a calming violin melody backed by a distorted guitar riff" and the model will generate a musical output. MusicLM can generate music at a consistent 24 kHz over several minutes.
The model works by taking audio snippets and maps them in a database of words that describe the music sounds (technically referred to as semantic tokens). It then takes the user’s text input, or even audio input, and generates the resulting sound. MusicLM examples can be sampled here.
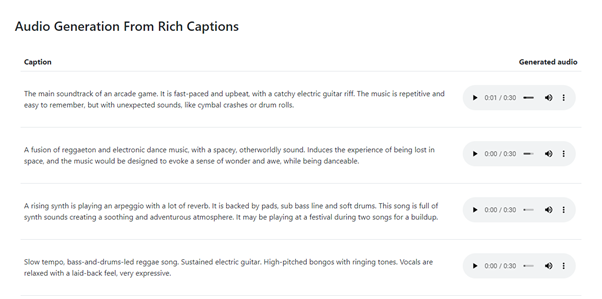
The Google researchers published the dataset used to train the model. Dubbed MusicCaps, the dataset is composed of 5,521 music examples, each of which is labeled with an English aspect list and a free text caption written by musicians.
Audio clips are then matched with audio clips from Google's AudioSet, which contains two million sound clips from YouTube videos. The text is focused on describing how the music sounds, not the metadata like the artist’s name. It can be accessed via Kaggle under a CC BY-SA 4.0 license.

MusicLM was also built using earlier Google AI models, AudioLM, SoundStream and MuLan. This latest model differs, however, in that it can generate around five minutes of audio, rather than mere snippets, with the researchers behind it stating MusicLM outperforms prior models “both in audio quality and adherence to the text description.
The Google research team also claims MusicLM outperforms other text-to-music models such as Mubert and Riffusion “both in terms of quality and adherence to the caption.”
Google’s paper notes that future work on text-to-music generation would focus on lyric generation, the improvement of text conditioning and vocal quality. The researchers also look to modeling the music at a higher sample rate as an additional goal.
You May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)