

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
How is Sora able to produce cinematic-quality videos? Here is how it works

OpenAI's new video generation model Sora is blowing away social media users with its cinematic-quality realism. It is so good that movie mogul and actor Tyler Perry paused an $800 million expansion of his studio after he saw what Sora could do, according to The Hollywood Reporter.
Perry called Sora "mind-blowing" and the capabilities it offers studios are "shocking to me."
"I no longer would have to travel to locations. If I wanted to be in the snow in Colorado, it’s text. If I wanted to write a scene on the moon, it’s text, and this AI can generate it like nothing," he said. "I don’t have to put a set on my lot. I can sit in an office and do this with a computer, which is shocking to me."
To generate Sora's jaw-dropping videos, OpenAI researchers used new techniques to enhance efficiency and versatility in generating high-quality videos. AI Business digs into what makes Sora so special.
Sora is a video generation model from OpenAI.
First unveiled in February 2024, Sora can use text, images and existing videos to create new videos.
Sora generates high-quality videos up to a minute long.
Videos created by Sora feature highly detailed scenes and complex camera motion. It can even add people to scenes.
Sora understands not only what the user has asked for in the prompt, but also how those things exist in the physical world.
The model has a context window of up to one million tokens – so users can use up to 700,000 words in a query.
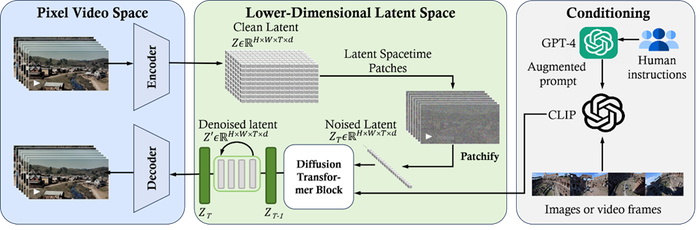
The technical paper outlining how the model works reveals that Sora is a diffusion transformer with flexible sampling dimensions.
The model’s inner workings can be split into three parts:
Credit: OpenAI
Sora generates a video but shrinks it down to make it easier to work with, effectively.
By splitting input data into “patches” which are then extracted to capture both the visual appearance and motion dynamics over brief moments.
Think of this step as sculpting clay, smoothing the edges to improve the final video’s quality.
Sora takes the compressed video and cleans it up. The ViT looks at the video data in its compressed form and figures ways to improve it, making the final video look better.
Here, the model takes user instructions – text or visual prompts – and uses those to add style or themes to the videos it generates. For example, if you asked for a sun setting over a beach, it would use this step to match the correct colors and elements with your prompt.
In essence, Sora first compresses a video to make it easier to work with, before cleaning it up and then taking user instructions to add final touches.

Prompt: A beautiful homemade video showing the people of Lagos, Nigeria in the year 2056. Shot with a mobile phone camera Credit: Tambay Obenson on X
Traditional diffusion models like Stable Diffusion largely leverage convolutional U-Nets. These break down into successive layers, focusing on smaller details to ensure its important features are understood.
With Sora, however, OpenAI opted for a more flexible transformer architecture, contending that U-nets are “not crucial to the good performance of the diffusion model.”
OpenAI’s approach with Sora saw it opt for a transformer-based diffusion model, which means it can handle more training data, resulting in a model with far larger parameters.
The decision to move away from U-nets resulted in a model that can efficiently process and generate complex video content, as the larger amounts of data used to train it means the model has more prior examples to learn from.

Credit: OpenAI
Sora can generate images in various sizes and resolutions ranging from 1920x1080p to 1080x1920p.
OpenAI achieved this by training the model on videos in their native sizes – arguing that training a model on videos cropped to squares “leads to unnatural compositions and framing.”
Videos generated by Sora have better framing – with the model able to create vertical videos, often used on social media, as well as horizontal. The resulting videos maintain subjects without cutting them out of the frame.
“Sora achieves a more natural and coherent visual narrative by maintaining the original aspect ratios,” the paper reads.
OpenAI took lessons from its DALL-E 3 image generation model and its ability to follow instructions.
Sora uses a similar approach to DALL-E 3, with the model paying close attention to the details in the instructions it is given.
OpenAI trained a descriptive captioner to describe objects in detail. That data was then used to refine the model, improving its ability to understand a wide range of user requests.
“This improved capability in prompt following enables models to generate output that more closely resembles human responses to natural language queries,” the technical paper reads.

Prompt: Ragdoll cat partying inside of a dark club wearing LED lights. the cat is holding the camera and video-taping the excitement, showing off his outfit. fish-eye lens Credit: AiBot via X
Sora is not without its flaws. The model struggles with simulating physics in complex scenes. For example, OpenAI found Sora struggled with capturing subtle facial expressions in some scenes.
The model outputs are also prone to instances of mistakes. For example, it might generate a video of someone taking a bite out of an orange, only for the bite marks to not be visible in the next frame.
There are also concerns about bias in Sora’s generated content. OpenAI said it is working to ensure the model’s outputs are “are consistently safe and unbiased.”
Sora is not available at the time of writing, with OpenAI opting to take “important safety steps” before making it available in products like ChatGPT.
OpenAI has enlisted a team of red teamers to scrutinize the model, assess critical areas for harm and risk.
A select group of visual artists, designers and filmmakers have been granted access, however, to provide feedback on the model.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)