

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Open source chatbot aimed at wider collaboration to correct deficiencies

ChatGPT could be looking at serious competition − not from Meta, Google or even Baidu, but Stanford University.
Stanford researchers said they have created a generative AI chatbot that “behaves qualitatively similarly to OpenAI’s text-davinci-003 (GPT-3.5)” while being “surprisingly small and easy/cheap to reproduce.”
It cost less than $600 to develop, according to the research team.
The chatbot is Alpaca 7B, a fine-tuned version of the seven billion-parameter LLaMA language model from Meta. The team took LLaMA 7B and finetuned it on 52k instruction-following demonstrations to create a ChatGPT-like chatbot. (Instruction-following models are those like ChatGPT that follows instructions from users to generate output.)
The researchers created Alpaca 7B to give academics an instruction-following model they can test, as the likes of OpenAI have close-sourced their models. By making it open source and available to any academic, the researchers believe faster progress can be made on addressing chatbot deficiencies such as generating falsehoods, biases and stereotypes.
“We hope that the release of Alpaca can facilitate further research into instruction-following models and their alignment with human values,” the team from Stanford said.
Alpaca shows many behaviors similar to OpenAI’s text-davinci-003, which was really an improved InstructGPT, one of the underlying models used to power ChatGPT. The differences: It is open source and cheap to develop.
Stanford researchers said they “generated instruction-following demonstrations by building upon the self-instruct method” – starting with 175 human-written instruction-output pairs from the self-instruct seed set. The researchers then “prompted text-davinci-003 to generate more instructions using the seed set as in-context examples.”
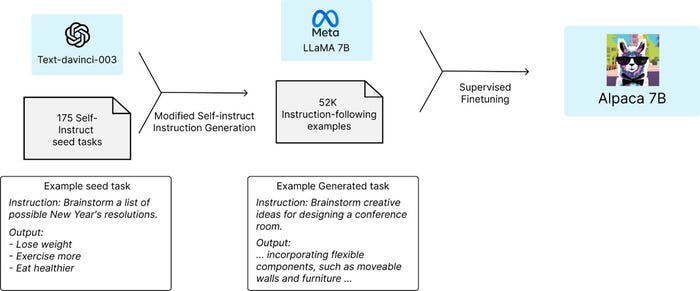
The team then “improved over the self-instruct method by simplifying the generation pipeline … and significantly reduced the cost,” with the data generation process creating 52k unique instructions to train the model, costing less than $500 using the OpenAI API.
The LLaMA models were then finetuned using Hugging Face’s training framework via “techniques like Fully Sharded Data Parallel and mixed precision training.” The team said it fine-tuned the 7B LLaMA model in just three hours on eight 80GB Nvidia A100 chips, which cost less than $100 on most cloud computing providers.
Essentially, the team from Stanford generated data from a language model, then input that data into another language model, fine-tuned it, and resulted in Alpaca 7B.
The team’s five authors evaluated Alpaca’s inputs so it covered a diverse list of user-oriented instructions including email writing, social media and productivity tools.
The researchers then “performed a blind pairwise comparison between text-davinci-003 and Alpaca 7B,” and found that these two models have “very similar performance: Alpaca wins 90 versus 89 comparisons against text-davinci-003.”
“We were quite surprised by this result given the small model size and the modest amount of instruction following data,” the researchers said. “Besides leveraging this static evaluation set, we have also been testing the Alpaca model interactively and found that Alpaca often behaves similarly to text-davinci-003 on a diverse set of inputs.”
The Stanford AI team did acknowledge that its evaluation may be limited in scale and diversity.
To further evaluate Alpaca, an interactive demo has been released with the researchers seeking feedback from the public, not too dissimilar to OpenAI with ChatGPT.
Like most language models, Alpaca suffers from hallucinations, toxicity, and stereotypes. The researchers acknowledge that it could be used to generate well-written outputs that spread misinformation.
“Alpaca likely contains many other limitations associated with both the underlying language model and the instruction tuning data. However, we believe that the artifact will still be useful to the community, as it provides a relatively lightweight model that serves as a basis to study important deficiencies,” the Stanford team said.
Alongside the demo, other releases include the data used to fine-tune Alpaca, the code for generating the data and the training code for fine-tuning the model using the Hugging Face API.
The researchers plan to release the Alpaca model weights, both for the 7B Alpaca and fine-tuned versions of the larger LLaMA models, but are waiting for guidance from Meta before doing so.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)