

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Facebook's parent company aims to encourage responsibility with open-source computer vision moves
.jpg?width=850&auto=webp&quality=95&format=jpg&disable=upscale)
Meta is expanding its open-source computer vision work to encourage the development of more responsible systems.
The Facebook parent announced it is making the DINOv2 computer vision model family available for commercial use.
Meta changed the model license to Apache 2.0, meaning it can be used in commercially licensed software or enterprise applications but Apache trademarks cannot be used in the licensed proprietary software or related documentation.
DINOv2 is a family of foundation models used to encode visual features. It uses self-supervision and can learn from any collection of images – including a depth estimation of an image.
“By transitioning to the Apache 2.0 license and sharing a broader set of readily usable models, we aim to foster further innovation and collaboration within the computer vision community, enabling the use of DINOv2 in a wide range of applications, from research to real-world solutions,” Meta’s AI team said.
Meta also announced it was releasing a collection of DINOv2-based dense prediction models for semantic image segmentation and monocular depth estimation.
The DINOv2 demo has also been given an overhaul, with users able to try its ability to estimate image depth, semantic segmentation and map all parts of an image without supervision via dense matching.
The DINOv2 demo can be accessed here - https://dinov2.metademolab.com/
Meta also unveiled a new benchmark for evaluating the fairness of computer vision models - FACET (FAirness in Computer Vision EvaluaTion).
Meta’s AI team said that benchmarking for fairness in computer vision was traditionally “hard to do.”
“The risk of mislabeling is real, and the people who use these AI systems may have a better or worse experience based not on the complexity of the task itself, but rather on their demographics,” Meta said in a blog post.
FACET is purely for research evaluation purposes. It cannot be used for training commercial AI models.
It is made up of 32,000 images containing 50,000 people, labeled by expert human annotators for demographic attributes. These include perceived gender presentation and additional physical attributes, such as perceived skin tone and hairstyle, and occupation and activity classes, for example, basketball player, guitarist or doctor.
FACET also contains person, hair, and clothing labels for 69,000 masks from the SA-1B dataset used to build its Segment Anything model.

Meta said it brought in “expert reviewers” to manually annotate the data related to demographic attributes. They defined bounding boxes for the people in the image and labeled fine-grained classes related to occupations and activities.
Meta hopes the test will be used to find out whether questions on model performance are related to human attributes, like whether detection models struggle to detect people whose skin appears darker.
“FACET can be used to probe classification, detection, instance segmentation and visual grounding models across individual and intersectional demographic attributes to develop a concrete, quantitative understanding of potential fairness concerns with computer vision models,” Meta said.
The FACET dataset can be accessed here - https://ai.meta.com/datasets/facet/
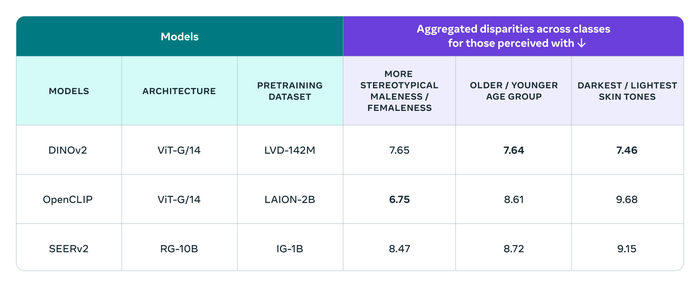
To showcase its new benchmark, Meta tested DINOv2 on FACET.
Its researchers found that DINOv2 performed worse than OpenCLIP, a web-crawled version of OpenAI’s CLIP model, when it came to perceived gender presentation.
DINOv2 performed better than OpenCLIP and Meta’s own SEERv2 model concerning perceived age group and skin tone, however.
The full results are below:
Meta said that FACT has enabled it to address potential shortcomings in the future by “diving deeper into the potential biases of the model at the level of classes.”
You May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)