

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
OpenHathi-Hi-v0.1 from Indian startup Sarvam AI can handle English, Hindi and Hinglish
.jpg?width=850&auto=webp&quality=95&format=jpg&disable=upscale)
Large language models can support multiple languages, but they are largely trained on English content. A new model has emerged hoping to serve Hindi-speaking users.
OpenHathi-Hi-v0.1 is a large language model from Sarvam AI, an Indian startup building generative AI solutions. Their new model surpasses OpenAI's GPT 3.5 Turbo in various Hindi tasks while maintaining its English performance.
OpenHathi-Hi-v0.1 is built atop the seven-billion parameter version of Llama 2, the popular open source model from Meta. The team at Sarvam extended its tokenizer to 48K tokens – which would allow the model to incorporate a broader range of languages or specialized vocabularies.
The model was trained in Hindi, English and Hinglish, a blend of Hindi and English. Sarvam contends that while open models like Llama and Mistral have democratized access to large language models, they have limited to no Indic language support – those are languages spoken by more than 800 million in countries such as India, Pakistan, Sri Lanka and Bangladesh.
The Indian startup assessed several models asking them to translate simple English sentences into Hindi. The models were able to output text in Devanāgarī, the script used for Hindi, but the models returned incorrect responses. For example, when inputting ‘the price of petrol has been on constant rise since a few years,’ the models incorrectly translated the phrase to 'There is a problem of too many workplace values’ from Mistral-7B.
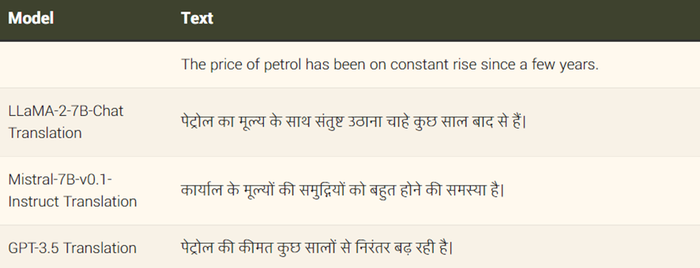
Credit: Sarvam AI
According to the language learning platform Babbel, Hindi is the fifth most popularly spoken language in the world, with some 344 million native speakers. The team that created OpenHathi wants the model to “encourage innovation in Indian language AI" and hopes others innovate on top of it by building fine-tuned models.
Training a model for Indic languages is a little harder than English.
Sarvam had to create a tokenizer solely to improve the model’s ability to handle Hindi, which saw the team train a sentence-piece tokenizer on a large corpus of Hindi text and integrate it with the existing tokenizer of the base model, Llama 2. The idea was to reduce the number of tokens generated for Hindi text to make both training and inferencing more efficient.
The startup also had to accommodate Romanized Hindi – a common way to write Hindi on an English keyboard.
Sarvam had to train the model to alternate sentences in Hindi and English to force the model to predict the input original text from its translation.
To address the lack of available training data, Sarvam translated English content to Hindi and used it for training. The startup also teamed up with I4Bharat, a research lab at the Indian Institute of Technology Madras, which provided language resources as well as benchmarks for building and testing the model.
Finally, the model was fine-tuned again for tasks like translation, content moderation and text simplification to improve its performance capabilities.
The resulting model outperformed GPT-3.5 and GPT-4 on the FLoRes-200 benchmark for translating Devanagari Hindi to English, though it did still trail behind IndicTrans2 and Google Translate.
OpenHathi also outperformed the OpenAI models in translating Romanized Hindi into English on the same test. The translation from and to Romanized Hindi was marginally more accurate than that for Devanagari Hindi – with Sarvam suggesting that using the English token embeddings of the base Llama model was “effectively shared between both English and Hindi content.”
While OpenHathi was competitive at translation tasks, Sarvam acknowledged that the model does have its limitations, notably, that it is susceptible to catastrophic forgetting. This is where a model that already has a base in one language and then continually trained with another language (Hindi) might lose its proficiency in the original language as it learns the new one.
OpenHathi-Hi-v0.1 can be downloaded via Hugging Face. It is a base model, with its creators saying it is not meant to be used as is: “We recommend first finetuning it on tasks you are interested in.”
The model uses the Llama 2 license, which means you can use it unless you are a hyperscaler.
Enterprise-grade versions of the model will be launching soon, Sarvam said in a company blog post.
The startup posted a video on their YouTube channel fully explaining the evaluation process.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)