

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
The OpenAI rival's Claude 3 multimodal models are more capable, accurate and offer competitive pricing

OpenAI rival Anthropic today unveiled its Claude 3 family of models, which is the startup’s first multimodal versions and geared towards addressing companies’ biggest generative AI concerns: cost, performance and hallucinations.
The startup, which boasts multi-billion dollar investments from Amazon and Google to take on the Microsoft-OpenAI juggernaut, unveiled three new models in its Claude 3 family: Haiku, Sonnet and Opus. These accept text and image inputs and return text.
The models show ascending levels of capability – Haiku, then Sonnet and Opus – as well as pricing. Notably, Anthropic’s technical paper on Claude 3 shows all three models beating OpenAI’s GPT-3.5 and Gemini 1.0 Pro in knowledge, reasoning, math, problem solving, coding and multilingual math.
Opus beats even GPT-4 and Gemini Ultra – OpenAI’s and Google’s most advanced models, respectively - according to Anthropic. Opus exhibits “near-human levels of comprehension and fluency on complex tasks, leading the frontier of general intelligence,” Anthropic researchers wrote in a blog post.
Anthropic said all three models initially have a 200,000 (200k) token window but are capable of ingesting more than one million tokens, available to select clients who need extra processing power.
But Opus is also the priciest of the three - $15 per million tokens (MTok) for input and $75/MTok for output. In contrast, OpenAI’s GPT-4 Turbo is cheaper at $10/MTok for input and $30/MTok for output but with a smaller context window of 128k.
Sonnet, which beats GPT-3.5 and is on par with GPT-4 on several metrics of performance, costs $3/MTok for inputs and $15/MTok for outputs. Haiku, the cheapest model at 25 cents/MTok input and $1.25/MTok output, comfortably beats GPT-3.5 and Gemini Pro but not GPT-4 or Gemini Ultra
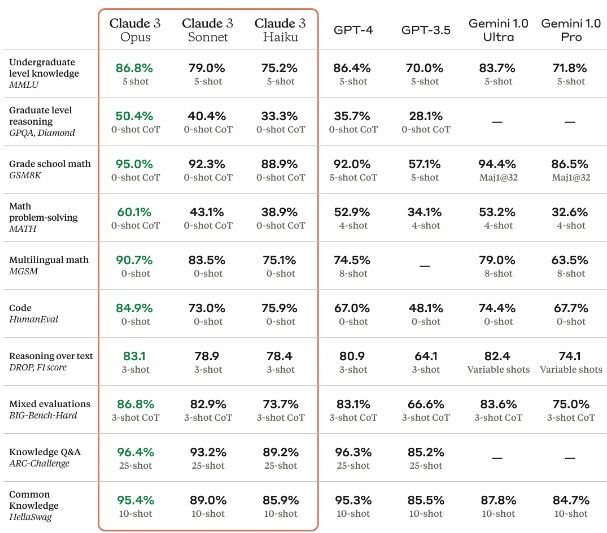
Credit: Anthropic
Claude 3 models were trained on data until August 2023 but can access search applications to get up-to-date information.
Opus and Sonnet are available now in claude.ai and the Claude API in 159 countries, with Haiku coming soon. Try Sonnet through the free version of the Claude AI chatbot here. Opus is available in the paid Claude Pro version. Here is the model card.
For enterprise customers, Sonnet is generally available only on Amazon Bedrock as a managed service. It is in private preview on Google Cloud’s Vertex AI Model Garden. Opus and Haiku are coming soon to both platforms.
Also coming to the models: function calling, interactive coding (REPL) and more advanced agent-like capabilities.
Anthropic is stepping up its commercial game by developing the Claude 3 models to appeal to enterprise customers, as the competition among language and multimodal AI models step up.
The Claude 3 models can do analysis, forecasting, content creation, coding and are multilingual. Adding the image capability will let businesses upload charts, graphics and other visuals into the models. (OpenAI did the same with GPT-4, unveiling GPT-4V that offers vision, too).
However, Anthropic pointed out that the Claude 3 models can give “near-instant responses” in real time that make it suitable for live customer chats, auto-completion and data extraction in which time is of the essence.
For example, it said Haiku can read a dense research paper with graphs of around 10k tokens in under three seconds, with faster speeds coming. Sonnet is twice as fast as Claude 2 and 2.1, making it more useful for knowledge retrieval and sales automation, among other tasks.
While Opus is the same speed as Claude 2 and 2.1, it is much more capable, Anthropic said.
One of the main concerns businesses have about generative AI is hallucinations, or incorrect outputs. Consider the recent case of Air Canada in which its AI chatbot gave incorrect refund information to a traveler. The airline was ordered by the court to make the traveler whole after he sued.
Anthropic said that Opus is twice as good as Claude 2.1 in giving correct answers and minimizing wrong answers. Researchers measured accuracy in three categories: correct answers, wrong answers and responding that it does not know the answer instead of answering incorrectly.
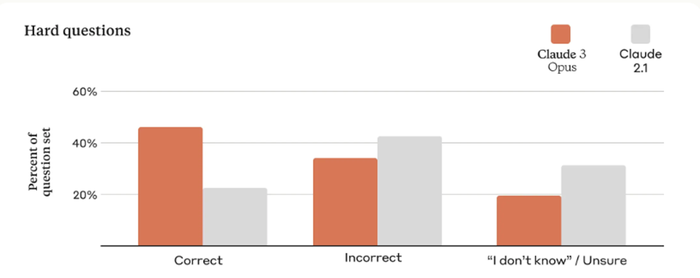
Crucially, Anthropic said the Claude 3 models have good recall of data in long context prompts – it said other AI models have trouble remembering the middle of long prompts. The startup claims that Opus has “near-perfect recall” with 99% accuracy.
That means Claude 3 models can better adhere to a brand’s voice and guidelines for customer-facing applications.
However, Claude 3 models cannot remember prompts from prior chats. It also cannot open links and will refuse to identify people in images.
Since its founding two years ago by former OpenAI engineers, Anthropic has prioritized making AI responsible. Its models are trained on what it calls ‘Constitutional AI,’ human values embodied in rules for the model to avoid sexist, racist and other toxic output and adhere to principles such as the U.N.’s Universal Declaration of Human Rights, according to the researchers.
Today, Anthropic announced another rule: respect for disability rights to mitigate any outputs that promote stereotypes and bias.
As for the risk of its models being used for nefarious reasons, the Claude 3 models are at AI Safety Level 2, which Anthropic said does “show early signs of dangerous capabilities – for example ability to give instructions on how to build bioweapons – but where the information is not yet useful due to insufficient reliability or not providing information that (for example) a search engine couldn’t.”
The Claude 3 models were trained on public online data and private data from third parties as well as its own data. Anthropic said its models do not access password-protected or gated sites or goes around CAPTCHA. User prompts and generated outputs are excluded from AI model training.
But Anthropic did decrease the levels of caution on these models. Prior models can be a bit too cautious by refusing to answer questions it deemed violated user policy.
It said Claude 3 models can better understand context and as such they are “significantly less likely to refuse to answer prompts that border on the system’s guardrails than previous generation of models."
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)