

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
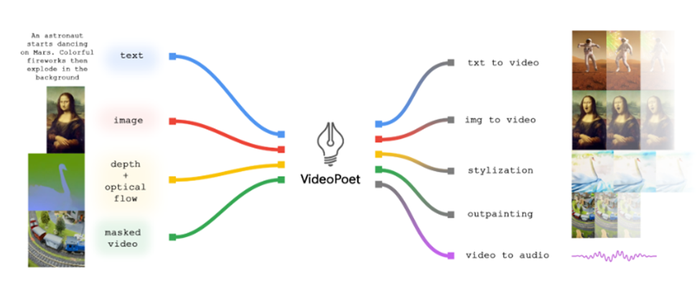
Unlike other video generation models, VideoPoet combines several video generation capabilities in one large language model

Google researchers have unveiled a large language model that can accept multimodal inputs – text, images, videos and audio – to generate videos.
Called VideoPoet, it has a decoder-only transformer architecture that is zero-shot, meaning it can create content it has not been trained on. It follows a two-step training process similar to that of LLMs: pretraining and task-specific adaptation. The pretrained LLM becomes the foundation that can be adapted for several video generation tasks, the researchers said.
Unlike rival video models that are diffusion models − meaning it adds noise to training data and then reconstructs it back − VideoPoet integrates many video generation capabilities within a single LLM without having separately trained components specializing in their tasks.
VideoPoet can perform text-to-video, image-to-video, video stylization, video inpainting and outpainting and video-to-audio generations.
Credit: Google
VideoPoet is an autoregressive model − meaning it generates output by looking back at what it had previously generated – trained on video, text, image and audio by using tokenizers to convert the input to and from different modalities.
“Our results suggest the promising potential of LLMs in the field of video generation,” the researchers said. “For future directions, our framework should be able to support ‘any-to-any’ generation, e.g., extending to text-to-audio, audio-to-video, and video captioning should be possible, among many others.”
See the website demo. VideoPoet is not yet publicly available.
Text prompt: Two pandas playing cards

Text prompt accompanying the images (from left):
1. A ship navigating the rough seas, thunderstorm and lightning, animated oil on canvas
2. Flying through a nebula with many twinkling stars
3. A wanderer on a cliff with a cane looking down at the swirling sea fog below on a windy day
Image (left) and video generated (immediate right)

Credit: Google
VideoPoet can also alter an existing video, using text prompts.
In the examples below, the left video is the original and the one right next to it is the stylized video. From left: Wombat wearing sunglasses holding a beach ball on a sunny beach; teddy bears ice skating on a crystal clear frozen lake; a metal lion roaring in the light of a forge.

Credit: Google
The researchers first generated 2-second video clips and VideoPoet predicts the audio without any help from text prompts.
VideoPoet also can create a short film by compiling several short clips. First, the researchers asked Bard, Google’s ChatGPT rival, to write a short screenplay with prompts. They then generated video from the prompts and then put everything together to produce the short film.
Google said VideoPoet can overcome the problem of generating longer videos by conditioning the last second of videos to predict the next second. “By chaining this repeatedly, we show that the model can not only extend the video well but also faithfully preserve the appearance of all objects even over several iterations,” they wrote.
VideoPoet can also take existing videos and change how the objects in it move. For example, a video of the Mona Lisa is prompted to yawn.

Credit: Google
Text prompts can also be used to change camera angles in existing images.
For example, this prompt created the first image: Adventure game concept art of a sunrise over a snowy mountain by a crystal clear river.
Then the following prompts were added, from left to right: Zoom out, Dolly zoom, Pan left, Arc shot, Crane shot, and FPV drone shot.

Credit: Google
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)