

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Meta's engineers share best practices to get the best results from their flagship open source large language model
.jpg?width=850&auto=webp&quality=95&format=jpg&disable=upscale "Photo of a llama")
When using a language model, the right prompt will get you the best results. Software engineers at Meta have compiled a handy guide on how to improve your prompts for Llama 2, its flagship open source model.
This guide provides a general overview of the various Llama 2 models and explains several basic elements related to large language models, such as what tokens are and relevant APIs.
These tips are published under Llama Recipes on the company’s GitHub page, Prompt Engineering with Llama 2. Here are six steps for getting the best out of Llama 2, from the company who created the model itself.
Input detailed, explicit instructions will produce better results than open-ended prompts.
Adding specific details, using precise details on the length of the output, like a character count, or employing a persona will return a far greater output.
For example, ‘summarize this document’ could yield undesirable results. However, being specific and even asking the model to respond in a relevant manner, like a persona, could drastically improve results, according to the guide.
Too general: ‘Summarize this document’
Better: ‘I'm a software engineer using large language models for summarization. Summarize the following text in under 250 words.’
Meta’s prompting guide offers tips on formatting prompts too, such instructing the model to respond using bullet points or generate less technical text.
Impose restrictions. By adding restrictions on your prompts, the model will likely generate an output closer to your request. For example, instructing Llama 2 to only use academic papers or not use a source older than 2020.
Too general: ‘Explain the latest advances in large language models to me’ will more likely cite sources from any period, making the output irrelevant to the request.
Better: ‘Explain the latest advances in large language models to me. Always cite your sources. Never cite sources older than 2020.’
Meta’s prompting guide states that giving Llama 2 a role can provide the model with context on the type of answers wanted.
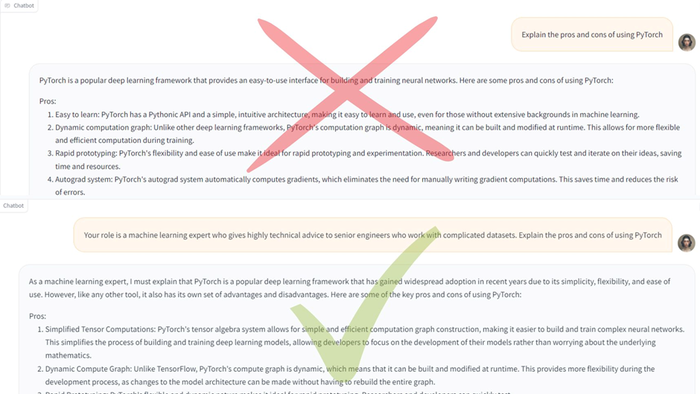
You want to use Llama 2 to create a more technical response on the pros and cons of using PyTorch.
Too general: Writing ‘Explain the pros and cons of using PyTorch’ would likely result in an overly broad and fairly generic explanation.
Better: Give the model a role – ‘Your role is a machine learning expert who gives highly technical advice to senior engineers who work with complicated datasets. Explain the pros and cons of using PyTorch.’
The result would be a far more technical response that includes details on more expert-level intricacies of PyTorch.
This is a simple consideration here from Meta, but one that could result in the model providing correct answers on a more consistent basis.
Add a phrase that encourages Llama 2 to employ step-by-step thinking to improve its reasoning.
The concept the guide references, CoT or Chain-of-Thought prompting, originates from a Google Brain paper.
Too general: ‘Who lived longer, Elvis Presley or Mozart?’ could result in the model wrongly picking Mozart.
Better: ‘Who lived longer, Elvis Presley or Mozart? Let's think through this carefully, step by step.’ By telling the model to think about it carefully, it is more likely to generate the correct answer, which is Elvis.
Even when you employ some of Meta’s prompting tricks, one single generation could produce incorrect results.
Enter ‘Self-Consistency,’ where the system regularly checks its own work to improve.
For example, the model could be encouraged to generate multiple responses or reasoning paths to a question and then evaluate these to determine the most consistent or correct answer.
‘List and explain the causes of the Spanish Civil War. Then, identify which cause was most significant and explain why.’
The model would generate several explanations or narratives related to the causes of the Spanish Civil War, and it would assess the narratives for consistency and coherence to identify the most significant cause based on the evaluation of these multiple perspectives.
The model would not just generate information but would be tasked with comparing and contrasting its own outputs in order to determine the most consistent and well-supported answer.

Llama 2, like other large language models, is only as good as the data used to train it.
If you want to extend the knowledge of a model to access external sources, Meta’s prompting guide suggests employing Retrieval-Augmented Generation, or RAG.
Llama 2 lacks specific knowledge about your company's products and services. With RAG, you can connect it to an external knowledge source, like a database of all your company's documents and product info – whether adding the document to the prompt itself or using a retrieval module.
Then, when asking Llama 2 a question, it will search the company database to find relevant information to use in its response.
Meta’s prompting guide states that employing RAG “is more affordable than fine-tuning, which may be costly and negatively impact the foundational model's capabilities.”
Models like Llama 2 can oftentimes generate irrelevant information or extraneous tokens.
Examples of extraneous tokens include ‘Sure! Here's more information on ...’
Cutting out this behavior can lead to more focused outputs that get right to the point.
Meta’s prompting guide states that to limit extraneous tokens, you will need to combine earlier tricks including assigning a role, employing rules and restrictions and providing explicit instructions.
Too general: ‘What is photosynthesis?’ would likely return a result that included extraneous tokens, like ‘Here is a definition of photosynthesis.’
Instead, use the earlier-mentioned techniques to help the model focus on the specific information.
Better: ‘Explain the process of photosynthesis in simple terms, focusing only on the key steps and elements involved.’
By employing Meta’s techniques, you can guide the model to provide a focused response without veering into unrelated topics or details.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)