

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Meta is offering AudioCraft, a family of text-to-audio and music models as open source to researchers and practitioners.

Continuing on its open source mission for generative AI, Meta’s latest offering is AudioCraft, a family of text-to-audio and music models.
AudioCraft consists of three models: MusicGen, AudioGen and EnCodec. The models are aptly named – MusicGen generates Meta-owned and licensed music from text prompts, AudioGen generates sound effects trained from public audio, while an improved version of EnCodec decoder enables “higher quality” music generation with fewer artifacts, according to the company.
Meta said this makes AudioCraft a "single-stop code base" for generative audio needs: music, sound effects and compression.
MusicGen models come in 300 million, 1.5 billion and 3.3 billion parameters. AudioGen comes in 285 million and 1 billion parameters.
Meta said in a blog post that generating music with AI has limitations given the use of symbolic representations like MIDI or piano rolls. These approaches are “unable to fully grasp the expressive nuances and stylistic elements found in music.” While there have been more recent advances, the company said “more could be done in this field.”
With AudioCraft, “people can easily extend our models and adapt them to their use cases for research,” according to Meta. “There are nearly limitless possibilities once you give people access to the models to tune them to their needs. And that’s what we want to do with this family of models: give people the power to extend their work.”
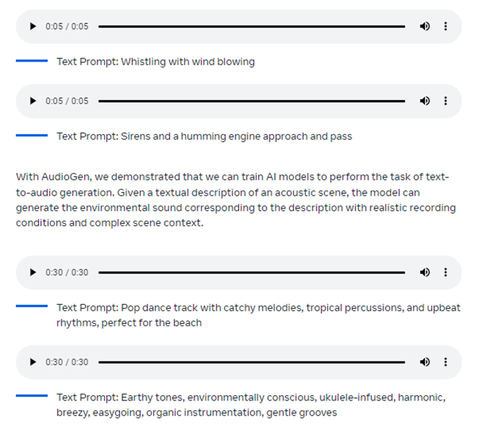
Credit: Meta
However, the company also admits that these datasets “lack diversity” since the music data contains a “large portion” of Western-style music with English text and metadata. Meta hopes that by open sourcing these models, the wider community can help limit or remove the bias altogether.
The models, and their weights and code, are available to researchers and practitioners under an MIT license, which allows for mostly unrestricted use, modification and distribution as long as the copyright notice and license terms are mentioned.
Access the AudioCraft code on GitHub. Try demos of MusicGen or listen to AudioGen samples. Read the EnCodec paper and download the code.
Meta’s researchers said generating audio based on the training dataset of raw audio signals is “challenging” because it requires modeling “extremely long sequences.” To solve this problem, the team took discrete audio tokens from the raw signal using EnCodec neural audio codec to get a new fixed “vocabulary” of music samples.
Then they trained autoregressive language models over these tokens to generate new tokens – which become new sounds and music when converting these tokens back to audio with EnCodec’s decoder.
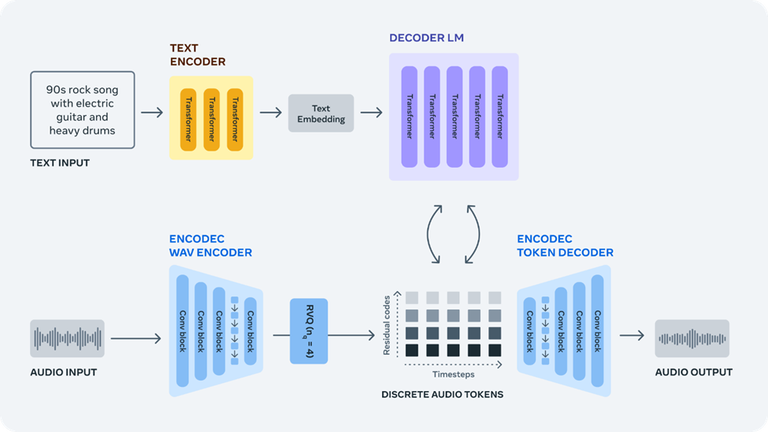
AudioCraft comes on the heels of Meta open sourcing its flagship language model, Llama 2, for research and commercial uses in mid-July. As of July 28, Meta said there has been an "incredible" response to Llama 2, with more than 150,000 download requests in its first week. The model was launched with its preferred partner, Microsoft, on Azure with support on Windows. It also is available on AWS and Hugging Face.
Meta said it has seen a "rapid pace" of adoption from Microsoft, Amazon, Qualcomm, Intel, Accenture, DoorDash, Dropbox, IBM, Nvidia, Shopify, Zoom and others.
"These companies are making a range of important contributions on Llama 2, from enabling increased performance and compatibility, to bringing it onto new devices, platforms, and environments to build on," said Ahmad Al-Dahle, vice president of GenAI at Meta, in a blog post. "And this is just the beginning of what I believe will be many more innovations to come."
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)