

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Longer context length is key

With greater demand for AI tools comes greater demand for systems to do more. Prompts for tools like ChatGPT that started out as a sentence or two are becoming increasingly complex. And the data being input for systems to analyze is unstructured.
Businesses could benefit from having a chat interface like ChatGPT or Bard capable of summarizing lengthy documents or sifting through customer data for insights. But to perform tasks like these, models would need to be trained on large amounts of data. And businesses have instead opted for smaller, more cost-effective models - which cannot handle such tasks well.
Open source models such as Meta’s LLaMA, Falcon-7B and MPT-7B have been trained with a maximum sequence length of around 2,000 tokens – or basic units of text or code − making their abilities to handle lengthy unstructured data like a document difficult.
Enter XGen-7B, a family of large language models from Salesforce that can handle lengthy document inputs more easily thanks to their training with “standard dense attention” on up to an 8,000 sequence length for up to 1.5 trillion tokens.
Salesforce researchers took a series of seven billion parameter models and trained them on Salesforce’s in-house library, JaxFormer, as well as public-domain instructional data.
The resulting model achieves comparable or better results when compared to open source models like LLaMA, Flacon and Redpajama.
AI researchers at Salesforce said the model cost just $150,000 to train on 1 trillion tokens using Google Cloud’s TPU-v4 cloud computing platform.
Salesforce’s model achieved some impressive results – scoring higher than popular open source large language models on a host of benchmarks.
When tested on the Measuring Massive Multitask Language Understanding (MMLU) benchmark, XGen achieved the best score in three out of the four tested categories, as well as in the weighted average. Only Meta’s LLaMA scored higher than XGen in the MMLU test covering the humanities.
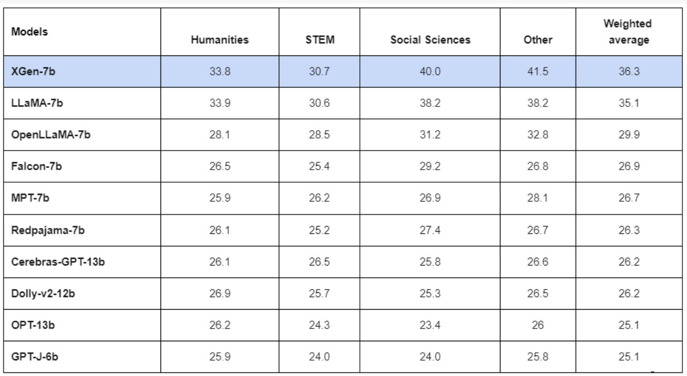
On the same benchmark's zero-shot test, XGen achieved similar results – again losing out to LLaMA on humanities.
In terms of overall zero-shot tests, XGen only outscored every other model in the TruthfulQA benchmark. Meta’s LLaMA did record better results on benchmarks including ARC_ch, Hella Swag and Winogrande.
However, on code generation tasks, XGen outclassed LLaMA and other models, scoring 14.20 on the HumanEval benchmark’s pass@1 metric. LLaMA could only muster 10.38.
Long-sequence tasks was where Salesforce’s new AI model shone the most – scoring incredibly well on the SCROLLS benchmark’s QMSum and GovReport datasets.
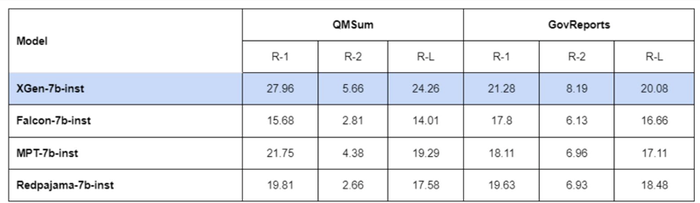
However, Salesforce’s researchers did note that since the XGen models are not trained on the same instructional data, “they are not strictly comparable.”
Salesforce’s researchers created three models - XGen-7B-4K-base, XGen-7B-8K-base and XGen-7B-inst.
XGen-7B-4K-base is capable of handling 800 billion context tokens, having been trained on 2,000 and later 4,000 sequence length tokens. It has been released under an Apache-2.0 license, meaning derivative works can be distributed under a different license, however, all unmodified components must use the Apache 2.0 license.
XGen-7B-8K-base saw the earlier mentioned model beefed up with a further 300 billion tokens, taking its total contextual understanding capability to 1.5 trillion tokens. This model was also released under Apache 2.0.
XGen-7B-inst was fine-tuned on public domain instructional data, including databricks-dolly-15k, oasst1, Baize and GPT-related datasets. The model was trained on both 4,000 and 8,000 tokens and has been released solely for research purposes.
To train the models, Salesforce’s researchers employed a two-stage training strategy, where each stage used a different data mixture.
The team explained: “For C4, we processed 6 Common Crawl dumps with C4 pipeline, and deduplicated the documents across different dumps by only keeping the newest timestamp for the documents with the same URL. We trained a linear model, which classifies the C4 data as a Wikipedia-like document vs. a random document. We then chose the top 20% Wikipedia-like documents.”
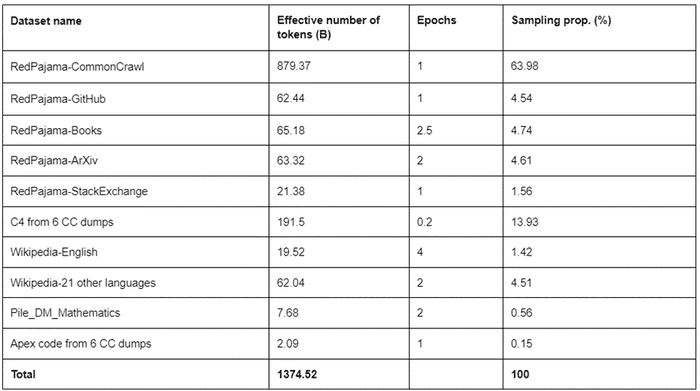
Starcoder, the code-generation model created by Salesforce and Hugging Face, was then added to support code-generation tasks. Core data from Starcoder was then mixed with the data from the earlier stage.
OpenAI’s tiktoken was then used to tokenize the model’s data. Additional tokens for consecutive whitespaces and tabs were later added.
While the XGen training process results in a series of powerful AI models, it is not without its flaws. Salesforce noted that the model still suffers from hallucinations.
For more on XGen-7B, Salesforce posted a detailed blog post on the model. The codebase for the model can be found on GitHub and the model checkpoints can be found on Hugging Face.
Models that are able to understand longer inputs could be a huge benefit for businesses.
Salesforce’s researchers said a large context “allows a pre-trained LLM to look at customer data and respond to useful information-seeking queries.”
For chatbot applications, more context means more conversation. And Salesforce isn’t the only organization looking into this concept. Anthropic, the high-rising AI startup founded by OpenAI alumni, recently expanded the context length of its flagship application, Claude.
Claude can now be used to recover information from multiple lengthy business documents or books, with users able to prompt the bot for questions on the data.
Current models struggle with increasing context lengths. As applications like ChatGPT and Bing’s AI chat began to emerge, users found the longer they used the model in a single conversation, the more unhinged its responses became. This was due to the model being unable to handle the context length, causing it to become confused and subsequently hallucinate.
Instances like Bing’s inappropriate responses reported in May forced Microsoft to limit the number of conversations users could have with the application as it simply could not handle long context conversations.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)