

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Cerebras’ open-source LLMs are an open rebuke to OpenAI’s closed models

Cerebras, the startup behind one of the world’s most powerful supercomputers, has thrown its hat into the large language model ring, unveiling seven open source models.
Dubbed Cerebras-GPT, the family of models ranges in size from 111 million parameters up to 13 billion parameters.
Trained using DeepMind’s Chinchilla formula, the models are designed for anyone to use at lower cost use as they consume less energy than any publicly available model to date, the startup said.
Cerebras decided to build and offer these open source models because it believes access should be more open. “The latest large language model – OpenAI’s GPT-4 – was released with no information on its model architecture, training data, training hardware or hyperparameters, Cerebras ML Research Scientist Nolan Dey wrote in a blog post.
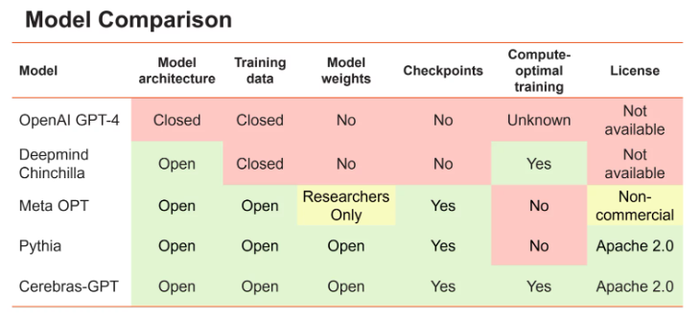
“Companies are increasingly building large models using closed datasets and offering model outputs only via API access,” he added. “For LLMs to be an open and accessible technology, we believe it’s important to have access to state-of-the-art models that are open, reproducible and royalty-free for both research and commercial applications.”
The models' datasets have not yet been made public. However, the models themselves can be accessed via HuggingFace.
Cerebras is best known for its WSE-2 chips, one of the biggest chips in the world in terms of physical size. They resemble an 8x8 inch slab, each containing 2.6 trillion transistors and 850,000 'AI-optimized' cores.
Cerebras’ CS-2 system contains a host of WSE-2 AI chips. The startup took 16 of those systems to power its AI supercomputer, Andromeda. Unveiled last November, Andromeda was designed to greatly reduce the time taken to train large language models.

The startup even claims the supercomputer can process large language models with enormous sequence lengths, something traditional GPUs simply cannot do. In an interview with AI Business late last year, Cerebras CEO Andrew Feldman said Andromeda has already helped with COVID-19 research.
The startup has turned its attention to large language models as a way to show what its tech can do.
The Cerebras-GPT models were trained on Andromeda, with Cerebras saying it was able to complete training “quickly, without the traditional distributed systems engineering and model parallel tuning needed on GPU clusters.” The cluster used to train the Cerebras-GPT models has also been made available in the cloud through the Cerebras AI Model Studio.
Cerebras contends the simplest way to scale AI training is using data-parallelism. Data parallel scaling replicates the model in each device and uses different training batches on those devices, averaging their gradients. Dey said that this method “does not address the issue of model size – it fails if the entire model does not fit on a single GPU.”
He explained: “A common alternative approach is pipelined model parallel, which runs different layers on different GPUs as a pipeline. However, as the pipeline grows, the activation memory increases quadratically with the pipeline depth, and this can be prohibitive for large models. To avoid that, another common approach is to split layers across GPUs, called tensor model parallel, but this imposes significant communication between the GPUs, which complicates the implementation and can be slow.”
“Because of these complexities, there is no single way to scale on GPU clusters today. Training large models on GPUs requires a hybrid approach with all forms of parallelism; the implementations are complicated and hard to bring up, and there are significant performance issues.”
Instead, Cerebras GPT was trained using standard data parallelism, combined with the startup’s CS-2 systems making it possible for enough memory to run large models on a single device without splitting the model.
Much has been made of major AI labs developing language models but then withholding information on how the underlying system works. OpenAI, for example, drew ire for unveiling GPT-4 earlier this month, only to reveal very few technical specifications, including no reference to the exact data used or size details.
Many, like AI researchers at Stanford, argue that because the likes of OpenAI have close-sourced their models, it makes it harder to conduct research into the potential effects of the technologies.
Cerebras designed its new models to provide that wider access, saying it hopes the models will “serve as a recipe for efficient training and as a reference for further community research.”
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)