

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Whisper v3 simplifies audio-to-text conversion for businesses, enhancing customer interaction and content generation
.png?width=850&auto=webp&quality=95&format=jpg&disable=upscale "Computer laptop with a smartphone next to it")
With over a million hours of training data, OpenAI's upgrades to its speech recognition system Whisper boasts advanced language understanding and significantly reduced error rates. The open source model can be used by businesses to upgrade their customer service, among other uses.
Unveiled during last week’s OpenAI DevDay, Whisper v3 offers improved performance in a wide variety of languages, with OpenAI adding a new language token for Cantonese.
First unveiled in September 2022, Whisper can translate audio snippets into text. It can be used for speech translation, language identification and even voice activity detection, making it suitable for voice assistant applications.
Whisper could be used to transcribe customer calls or generate text-based versions of audio content.
When combined with OpenAI’s text generation models, like the new GPT-4 Turbo, developers could build powerful dual-modal applications.
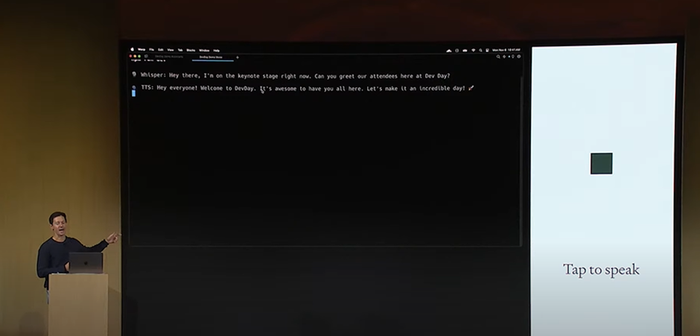
Romain Huet, OpenAI's head of developer experience, showed how combining Whisper with other OpenAI solutions could be used to power apps. He used Whisper to convert voice inputs into text along with the new GPT-4 Turbo model to power an assistant option and the new Text-to-speech API to make it speak.
The first version of Whisper was trained on 680,000 hours of data. The new Whisper v3 was trained on a whopping five million hours of audio – one million was weakly labeled (only identifying what is the sound) and four million pseudo labeled (using a model trained on labeled data to predict labels for unlabeled data).
It is built on a Transformer sequence-to-sequence model that essentially processes a sequence of tokens that represent audio data and decodes it to produce the desired output. In simple terms, it takes audio and breaks it down into pieces, then uses those pieces to figure out what's being said.
Whisper v3 comes in a variety of sizes, so users can apply the relevant size needed for their application. The smallest, Tiny, comes in at 39 million parameters and requires around 1 GB of VRAM to run. The base version stands at 74 million parameters and is around 16 times faster at processing audio than the previous model. The largest, the aptly named Large, stands at a whopping 1550 million parameters and needs 10 GB of VRAM to run.
Tested on audio model benchmarks such as Common Voice 15 and Fleurs, OpenAI said Whisper v3 achieves much lower error rates than the previous Whisper models, released in December 2022.
“We think you're really going to like it,” OpenAI CEO Sam Altman said of the new Whisper during his DevDay keynote.
Whisper is open source – You can access it via Hugging Face or GitHub.
Whisper v3 can be used for commercial purposes – it is available under an MIT license, meaning businesses can use Whisper v3 provided they adhere to conditions stated in the license, including the copyright and permission notices in all copies.
The license, however, comes with no warranties and places no liability on the authors or copyright holders for any issues that may arise from its use.
While Whisper is open source, OpenAI said it plans to support the newest version of its automatic speech recognition model via its API “in the near future.”
However, OpenAI notes the model achieves lower accuracy on languages with limited available training data. Whisper’s performance also suffers when it comes to different accents and dialects of particular languages which leads to a higher word error rate.
You May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)