

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
With positional encoding tweaks and continual pretraining, the new open source Llama 2 Long now excels at long inputs
.jpg?width=850&auto=webp&quality=95&format=jpg&disable=upscale "Image of a llama")
Meta has upgraded its flagship open-source Llama 2 large language model to improve its ability to handle lengthier inputs.
Researchers unveiled Llama 2 Long in a paper, contending it is on par with proprietary models that have longer context windows such as Claude 2 from Anthropic, while remaining open source.
Llama 2 Long can handle texts up to 32,768 tokens – with larger versions of the model able to deal with contexts more effectively. The upgraded model surpasses the original version on both long context tasks like summarization, question-answering and aggregation as well as on standard short-context benchmarks.
Llama 2 Long could be used to sift through longer documents than its predecessor, handling content like financial documents or sales reports to extract insights.
At the time of writing, it is not out yet – AI Business has contacted Meta for clarification.
Meta's researchers were able to improve Llama 2 by pretraining the model on an additional 400 billion tokens. The resulting model improved both long- and short-context tasks.
Llama 2's original architecture was kept largely intact before pretraining, though Meta did modify the model's positional encoding. The original model’s positional encoding system caused attention scores to decay for distant tokens, which limited the model’s context length.
The team also chose not to apply sparse attention – which reduces computation time and memory requirements of a model's attention mechanism but can complicate the inference pipeline – to avoid computational bottlenecks.
The model’s pretraining process involved using pre-trained Llama 2 checkpoints and additional long text sequences. The model was then further refined using a mixed dataset of human-annotated instructions and synthetic instructions generated by Llama 2 itself. The researchers contend this method improved Llama 2’s performance on downstream tasks without needing expensive human labels.
On various benchmark tests, Llama 2 Long outperformed the original Llama 2. For example, on the popular MMLU benchmark (Massive Multi-task Language Understanding test that covers 57 tasks including basic math, computer science, law and other topics), Llama 2 Long scored 71.7 whereas Llama 2 only scored 68.9 in a 70-billion parameter model.
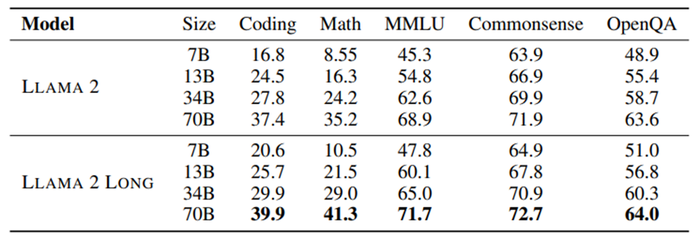
When compared with closed models, Llama 2 Long outperforms OpenAI’s GPT-3.5 on both MMLU and the GSM8k test (Grade School Math 8K).
The researchers propose that Llama 2 Long’s improved performance on shorter tasks stems from the knowledge it has learned from the newly introduced long data.
However, Llama 2 Long does lose out on short tasks to the likes of OpenAI's GPT-4 and Google's PaLM 2 based on the metrics disclosed by their creators. Meta researchers could not run the tests themselves since those competing models are closed.

Llama 2 Long generally does outshine its rivals on longer tasks. Compared with other open source long-context models, the new model scored well across its different sizes with one exception. The larger 70 billion parameter version, for example, scored 30.9 on the NarrativeQA F1 zero-shot test, whereas MPT-30B (22.9), Yarn-13B (23.4) and Xgen-7B (18.8) all scored lower. However, Llama 2 Long's 7 billion-parameter model does not always outperform its rivals.

Llama 2 Long does have its flaws – for one, it struggles with whitespace, making the model inefficient at processing long code data.
And despite its new-found ability to handle lengthier documents, Llama 2 Long has not been finetuned for certain long-context applications, like creative writing.
It also struggles with what the researchers call “a relatively small vocabulary,” meaning it produces longer sentences compared to OpenAI’s base ChatGPT model, GPT 3.5.
The model, like all generative AI systems, does hallucinate. However, Meta's researchers performed red teaming exercises to assess the vulnerability of the model. They found no significant risks as compared to the chat-refined version of Llama 2.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)