

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Meta wants to build a universal translator – you can try its latest attempt for yourself
.jpg?width=850&auto=webp&quality=95&format=jpg&disable=upscale)
Meta has debuted SeamlessM4T, a new multimodal AI model that can translate audio into text and text to speech.
The new model supports around 100 languages and can perform:
Automatic speech recognition
Speech-to-text translation
Speech-to-speech translation
Text-to-text translation
Text-to-speech translation
Meta’s AI team said in a blog post unveiling SeamlessM4T, that the new model “is an important breakthrough in the AI community’s quest to create universal multitask systems.”
The team plans to explore how SeamlessM4T can evolve to “enable new communication capabilities—ultimately bringing us closer to a world where everyone can be understood.”
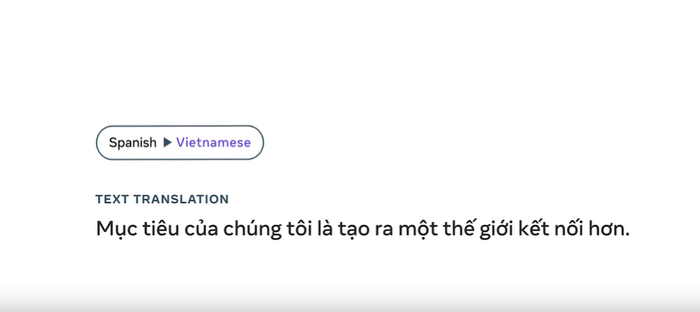
Meta is giving a public release under a CC BY-NC 4.0 license. The company wants researchers and developers to “build on this work.”
It is also releasing the metadata for SeamlessAlign, a multimodal translation dataset built to power the model. SeamlessAlign encompasses a total of 270,000 hours of mined speech and text alignments.
You can download the code, model and data here.
You can give SeamlessM4T a go via two interactive demos.
Meta has built a test environment for you to try SeamlessM4T. It’s accessible here: https://seamless.metademolab.com/
How to use the demo:


The demo is not without its flaws, however, as Meta notes that it can produce translations that are not accurate or change the meaning of the words you've spoken. As you can see above, the results widely differ – from talking about trumpets in English to the formation of the UAE in Dutch, when the input was talking about the video game Among Us.
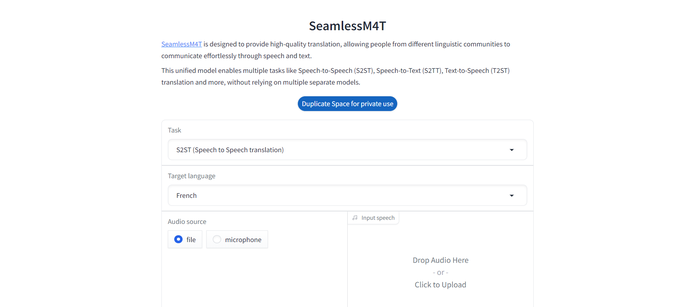
There’s also a demo to try via HuggingFace - https://huggingface.co/spaces/facebook/seamless_m4t
Users can try out the different variations of tasks SeamlessM4T can perform and can listen to examples in French, Spanish, Hindi and Mandarin Chinese.
With the Hugging Face demo, users can drop audio files in for the model to translate or even record new input via their device’s microphone.
In its SeamlessM4T announcement, Meta’s AI researchers explore the possibility of building a universal language translator akin to the Babel fish in The Hitchhiker’s Guide to the Galaxy.
The challenge to achieve this is that speech-to-speech and speech-to-text systems “only cover a small fraction of the world’s languages,” Meta’s researchers contend, adding that as such models leverage large amounts of data, they generally perform well for only one modality.
To build SeamlessM4T, Meta’s AI researchers took Fairseq, its sequence modeling toolkit, and redesigned it with more efficient modeling and data loader APIs.
For the model, Meta used the multitask UnitY model architecture, which is capable of directly generating translated text and speech. UnitY supports automatic speech recognition, text-to-text, text-to-speech, speech-to-text and speech-to-speech translations that are already a part of the regular UnitY model.
The multitask UnitY model consists of three main sequential components. According to Meta: “Text and speech encoders have the task of recognizing speech input in nearly 100 languages. The text decoder then transfers that meaning into nearly 100 languages for text followed by a text-to-unit model to decode into discrete acoustic units for 36 speech languages.
“The self-supervised encoder, speech-to-text, text-to-text translation components, and text-to-unit model are pre-trained to improve the quality of the model and for training stability The decoded discrete units are then converted into speech using a multilingual HiFi-GAN unit vocoder.”
The model’s self-supervised speech encoder, w2v-BERT 2.0, an improved version of w2v-BERT, finds structure and meaning in speech by analyzing millions of hours of multilingual speech.
The encoder then takes the audio signal, breaks it down into smaller parts and builds an internal representation of what’s being said. Meta then applies a length adaptor to map words.
SeamlessM4T also contains a text encoder, based on Meta’s NLLB (No Language Left Behind) model. This text encoder has been trained to understand text in nearly 100 languages.
Among the additional tools used to train SeamlessM4T, Meta created a text embedding space called Sentence-level mOdality- and laNguage-Agnostic Representations (SONAR).
SONAR can support up to 200 languages and be used to automatically align more than 443,000 hours of speech with texts and create about 29,000 hours of speech-to-speech alignments.
Combined with its new SeamlessAlign dataset, Meta’s researchers claim to have created the “largest open speech/speech and speech/text parallel corpus in terms of total volume and language coverage to date.”
SeamlessM4T achieves results for nearly 100 languages, according to Meta.
To test the system, the researchers applied the model on the BLASER 2.0 evaluation and found the model performed better against background noise and speaker variations in speech-to-text tasks with average improvements of 37% and 48%, respectively.
SeamlessM4T was found to outperform AI models including Whisper v2 from OpenAI and AudioPaLM-2 from Google.
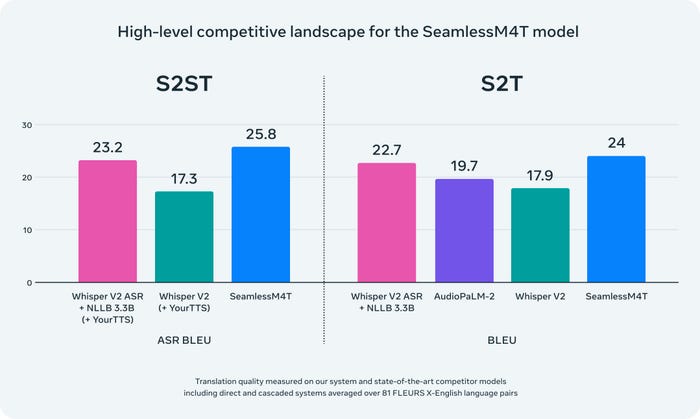
Full results can be found in the SeamlessM4T paper.
Meta’s team acknowledged upon unveiling SeamlessM4T that, like with most AI systems, there's a risk it could be used for toxic purposes.
When building SeamlessM4T, Meta identified potentially toxic words from speech inputs and outputs using a multilingual toxicity classifier. Unbalanced toxicity was then filtered out of the trained data.
Meta said it can detect toxicity in both the input and the output of its SeamlessM4T demos, adding: “If toxicity is only detected in the output, it means that toxicity is added. In this case, we include a warning and do not show the output.”
The team behind said they were also able to quantify gender bias in speech translation directions by extending its previously designed Multilingual HolisticBias dataset to speech.
Meta pledged to continue to research and take action against toxicity in speech recognition and plans to continuously improve SeamlessM4T and reduce any instances of toxicity in the model.
Read more about:
ChatGPT / Generative AIYou May Also Like


.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)