

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
The 'Society of Minds' approach can reduce AI model hallucinations and improve results

A team of MIT researchers found that having multiple AI systems debate answers to questions leads to improved accuracy in responses compared to just using a single AI system.
In a paper titled Improving Factuality and Reasoning in Language Models through Multiagent Debate, the researchers found that leveraging multiple AI systems processes helps correct factual errors and improve logical reasoning.
The MIT scientists, along with Google DeepMind researcher Igor Mordatch, dubbed the process a "Multiagent Society” and found that it reduced hallucinations in generated output. The approach can even be applied to existing black-box models like OpenAI’s ChatGPT.
The process sees various rounds of responses generated and critiqued. The model generates an answer to a given question and then incorporates feedback from other agents to update its own response. The researchers found this process improves the final output as it is akin to the results of a group discussion – with individuals contributing a response to reach a unified conclusion.
The method can also be used to combine different language models – the research pitting ChatGPT against Google Bard. While both models generated incorrect responses to the example prompt, between them, they were able to generate the correct final answer.

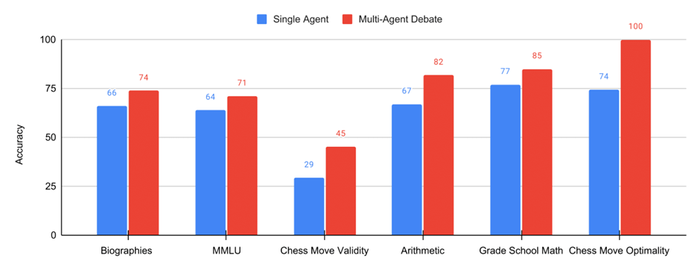
Using the Multiagent Society approach, the MIT team was able to achieve superior results on various benchmarks for natural language processing, mathematics and puzzle solving.
For example, on the popular MMLU benchmark, using multiple agents scored the model an accuracy score of 71, while using only a sole agent scored 64.
“Our process enlists a multitude of AI models, each bringing unique insights to tackle a question. Although their initial responses may seem truncated or may contain errors, these models can sharpen and improve their own answers by scrutinizing the responses offered by their counterparts," Yilun Du, an MIT Ph.D. student and the paper’s lead author.
"As these AI models engage in discourse and deliberation, they're better equipped to recognize and rectify issues, enhance their problem-solving abilities, and better verify the precision of their responses.”
You can access the code used in the multiagent project on GitHub.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)