



Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
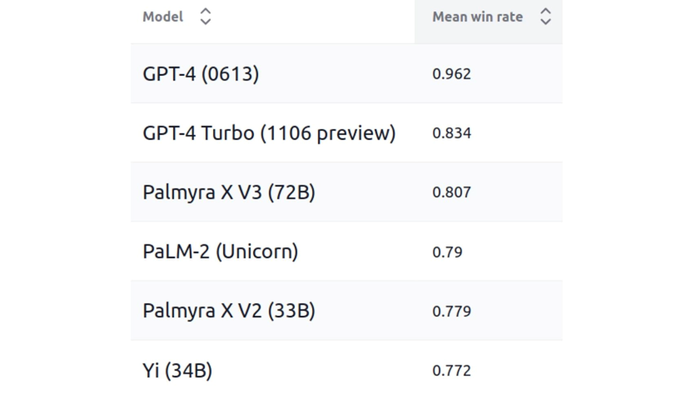
Google’s PaLM 2 was beaten by Palmyra X V3, an open source model from AI startup Writer

In a surprise, a foundation model from AI startup Writer has trumped Google in the latest ranking of foundation model performance by Stanford University researchers.
Palmyra X V3 from AI startup Writer outperformed Google’s PaLM 2 as the highest-scoring non-OpenAI model on the leaderboard of Stanford’s Holistic Evaluation of Language Models (HELM) Lite.
Its 72 billion-parameter model outperformed rivals despite being much smaller than other models on the list. Palmyra ranked third on the HELM leaderboard, while PaLM 2 was fourth.
Another surprise was Yi-34B, an open source 34 billion-parameter model from 01.ai, a Chinese startup founded by visionary Kai-Fu Lee. Trained on three trillion tokens, the model finished higher on Stanford’s leaderboard than Mistral 7B, Anthropic’s Claude 2 and even Meta’s Llama 2.
Predictably, OpenAI’s GPT-4 topped the Stanford list by a decent margin. The model, released last March, achieved top scores on benchmarks including OpenbookQA, for answering questions on elementary science facts, MMLU covering general standardized exam questions, and LegalBench, where the model performs tasks that require legal interpretation.
OpenAI’s GPT-4 Turbo came in second. Unveiled at DevDay 2023, the model was designed to be cheaper to run and capable of handling 16 times more text than GPT-4. GPT-4 Turbo finished lower than its earlier counterpart as it failed to follow instructions well.
Percy Liang, an associate professor of computer science at Stanford University, tweeted that smaller models “unexpectedly” outperformed the larger models. "Some recent models are very chatty: they sometimes output the correct answer in the wrong format, even when instructed to follow the format."
The HELM Lite test was designed to be lightweight yet broad. Stanford had previously published the HELM framework, with this latest test focusing solely on capabilities. The university’s researchers are planning to cover model safety in a new benchmark that is being developed in partnership with MLCommons.
HELM Lite tests models across a variety of capabilities such as machine translation, medicine and questions about books. The project was inspired by the Open LLM leaderboard from Hugging Face, in which Yi-34B currently sits at the top.
The Stanford team did not get access to closed-system models such as GPT-4 and Claude. Instead, they used the standard interfaces and carefully crafted their prompts to “coax them to generate outputs in the proper format.”
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)