

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
Vectara also released its open source model that lets anyone check the hallucination rates of their large language models
.png?width=850&auto=webp&quality=95&format=jpg&disable=upscale "Abstract image")
OpenAI’s GPT-4 has the lowest hallucination rate of large language models when summarizing documents, a new leaderboard from Vectara suggests.
The Palo Alto-based company launched a leaderboard on GitHub that evaluates some of the biggest names in large language models on its Hallucination Evaluation Model, which gauges how often an LLM introduces hallucinations when summarizing a document.
GPT-4 and GPT-4 Turbo came out on top with the highest accuracy rate (97%) and lowest hallucination rate (3%) of any of the tested models.
Another OpenAI model scored the second highest: GPT 3.5 Turbo, the newest iteration of the model that powers the base version of ChatGPT. GPT 3.5 Turbo scored an accuracy rate of 96.5% and a hallucination rate of 3.5%.
The highest-scoring non-OpenAI model was the 70 billion parameter version of Llama 2 from Meta, with an accuracy score of 94.9 % and a hallucination rate of just 5.1 %.
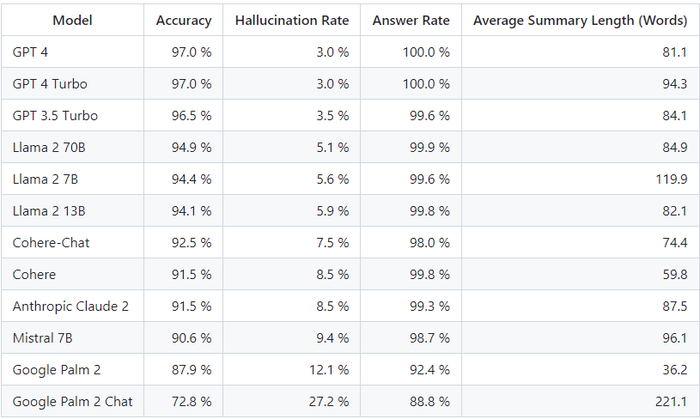
The worst-performing models came from Google – Google Palm 2 had an accuracy rate of 87.9 % and a hallucination rate of 12.1 %. The chat-refined version of Palm scored even lower, achieving an accuracy rate of just 72.8 % and the highest hallucination score of any model on the board with 27.2%.
Google Palm 2 Chat generated the highest average amount of words per summary, with a whopping 221. In comparison, GPT-4 generated just 81 words per summary.
Vectara trained a model to detect hallucinations in large language model outputs using open source datasets. The company fed 1,000 short documents to each of the models via their public APIs and asked them to summarize a short document, using only the facts presented in the document.
Of the 1000 documents, only 831 were summarized by every model, the remaining documents were rejected by at least one model due to content restrictions. Using the documents accepted by every system, Vectara then computed the overall accuracy and hallucination rate for each model.
None of the content sent to the models contained illicit or 'not safe for work' content but the presence of trigger words was enough to launch some of the content filters.
The risk of hallucinations has held back many businesses from adopting generative AI, Shane Connelly, head of product at Vectara, wrote in a blog post.
“Some attempts have been made in the past to quantify or at least qualify when/how much a generative model is hallucinating. However, many of these have been too abstract and based on subjects that are too controversial to be useful to most enterprises.”
The company’s Hallucination Evaluation Model is open source – meaning companies can use it to evaluate the trustworthiness of their large language models in Retrieval Augmented Generation (RAG) systems. It can be accessed via Hugging Face, with users able to tune it for their specific needs.
“Our idea is to empower enterprises with the information they need to have the confidence they need to enable generative systems through quantified analysis,” Connelly wrote.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)