



Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
A research paper from City University of Hong Kong academics

ChatGPT is capable of many astounding feats that have stirred debates on the future of jobs, copyright, deep fakes, and what it means to be human. But can it do data science? This is a do-or-die question for all data scientists, statisticians, quant jocks, economists, and quantitative folks.
Recently, we put ChatGPT to the test by prompting it to do basic data science at a master’s level course at our university. We asked ChatGPT to help design a survey dataset that would let students practice different types of statistical analysis. The dataset would focus on various constructs that predicts public service success and citizen satisfaction.
Students could tinker with the dataset to practice different types of statistical analysis: mediation analysis, to reveal the hidden mechanism between two variables; moderation analysis, to examine how different factors influence the relationship between two variables; and moderated mediation analysis, which combines both mediation and moderation to offer a more comprehensive understanding of the relationship between variables of interest.
To create the survey dataset, we gave ChatGPT certain instructions: how many variables need to be included in the dataset, both dependent (DV) and independent (IV) variables, as well as some control variables. Also, we told ChatGPT how many observations we wanted in the dataset and how each variable should be measured: metric, interval, ordinal, or categorical scale. Finally, we tasked it to introduce some realistic issues in the dataset, such as non-normal distributions and missing values.
If ChatGPT is successful, it would save data scientists, academics and researchers much time and effort in creating data from scratch for learning purposes. This could also be a novel and useful application of ChatGPT for data science practices.
The challenge: We asked ChatGPT to write Python or R code to produce the dataset, which can be copied to a Python or R text editor to generate the dataset based on several specifications. These include public service success and citizen satisfaction as possible dependent variables; possible independent and control variable such as social skills, compassion, age, gender, education and prior work experience; among others.
Based on the rather complex prompts above, can ChatGPT produce a data matrix? Can it produce the required Python or R code without errors?
First, we entered the following prompt to ChatGPT:

Observation #1: The Python code appears to be correct (see the Python interpreter screenshot below). It used NumPy to generate variables with normal or skewed distributions, ordinal scale (for education), binary values (for gender) or missing values. Next, it created the mediation pathways by presuming the coefficients of each path, either positive or negative. In the end, it used pandas to create a data frame using the required variables. We then copied and pasted the code to the Python text editor and tested whether it can really produce the required dataset.
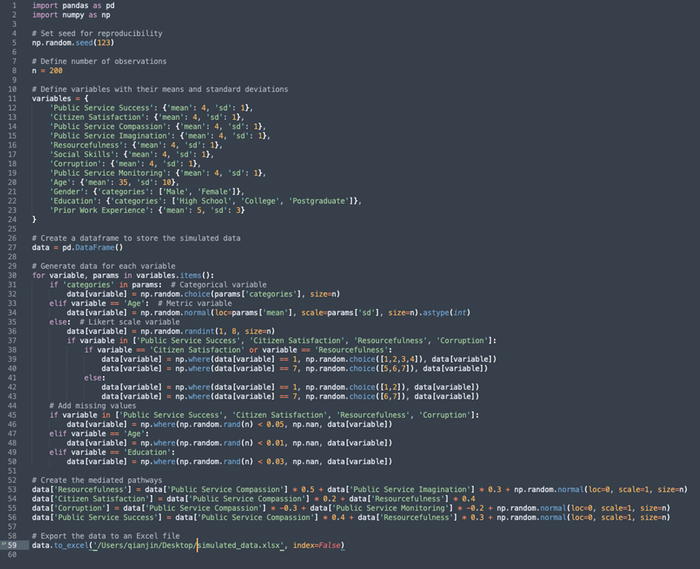
Observation #2: The Python code above worked well without any error (see the Excel screenshot below). But we found some imperfections from a quick scan. For example, we required that all values should be integers, however, values of “public service success,” “citizen satisfaction,” “resourcefulness” and “corruption” are still floats. We also spotted that “public service success” and “corruption” have negative values, while we didn’t specify that these two variables should have extreme values, instead, they should range from 1 – 7 and be integers.

We then test the correlations and mediations using RStudio. It turns out that the simulated dataset generated by ChatGPT using the Python code above conforms to our specifications. The correlations among the variables are shown in the Excel table below, with * that indicates the correlations that are statistically significant.

We then ran several regressions using Lavaan package in R. The result is shown below.
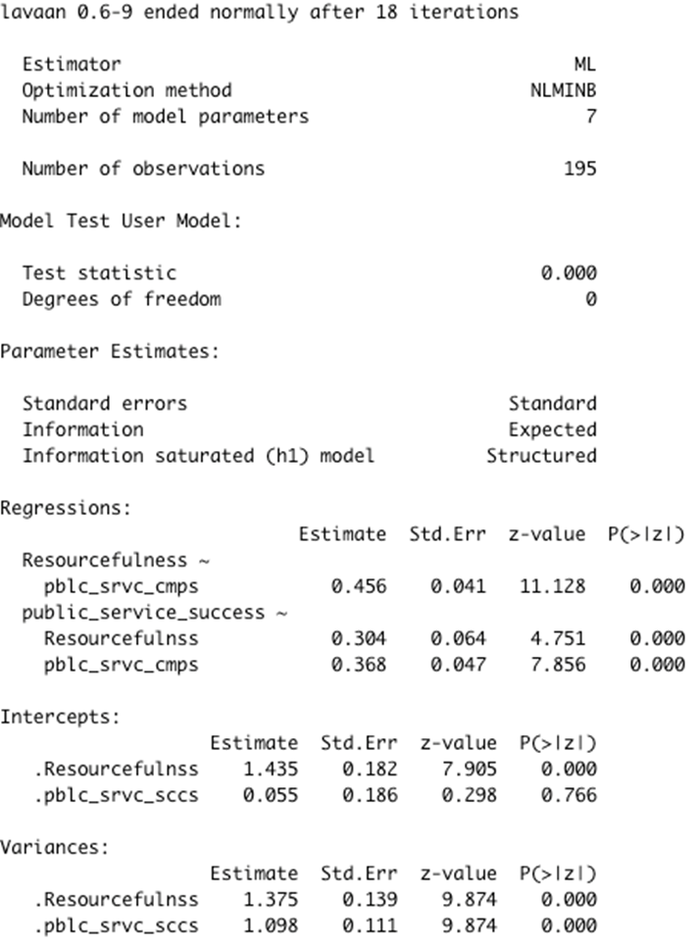
We found that a very interesting use case of ChatGPT is to help users create examples to facilitate data science practice and learning purposes. We demonstrated this with an example matrix dataset created using ChatGPT. Data science learners and practitioners can learn how to use ChatGPT by creating their own dataset as a way of learning about data and statistical methods. But can ChatGPT do data science? At a broad level, ChatGPT passed the test. But there is more nuanced interpretation of ChatGPT’s capability.
First, while ChatGPT is a versatile tool for creating codes in mere seconds for use in statistical programming tools such as Python and R, it is yet to be error free. Users must conduct due diligence to check and verify code accuracy, correct use of packages and pandas, etc.
When users have too many specifications in one prompt, ChatGPT may ignore parts of the specifications in generating the code. We noticed this when we tried the first prompt multiple times. It is impressive that ChatGPT gave different codes each time, but we also realized that not every code worked perfectly; there might be some errors. Therefore, it still requires the prompters to inspect the codes to ensure that each specification has been covered in the codes before running it. So, if you want to get the best results from ChatGPT, always verify for code accuracy and completeness.
Second, using the same prompts and specifications above we tested how Python and R codes fare. We found that the R codes generated by ChatGPT were more likely to contain errors than those in Python. We even found that ChatGPT might fool us − or hallucinate − by giving non-existent functions in R. For example, it claimed that the package lavaan (an R package for structural equation modelling) has a sim function to produce simulated datasets, but this function does not exist at all (we acknowledge that the correct name of this function should be simulateData). So, if you want to use ChatGPT to generate R code, always double-check the code before running it.
Lastly, we found that ChatGPT has a space limitation in giving responses. When the code has too many lines, it will stop generating and end up providing incomplete code. In this situation, we can give prompts in stages and ask it to ‘continue’ to finish. So if you want to generate long code with ChatGPT, it is a good practice to break it down into smaller prompts and use the ‘continue’ prompt when necessary.
Overall, the good news is that data science work cannot yet be fully automated by AI. ChatGPT has pedagogical value to assist with teaching and learning in the introductory data science. But it is still prone to some limitations. However, there is still plenty of mystery with regard to its capabilities for data science as AI’s capabilities develops rapidly. We merely scratched the surface of AI for data science. Our playful exploration was only a first step in the ChatGPT face-off. It would be fun to see how future language models and data science intersect.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)