

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
New framework enables multimodal large language models to better understand the context of inputs

Large language models are becoming multimodal, with ChatGPT getting the ability to see, hear and speak. But to get better outputs, the model needs a universal generative model that simultaneously learns language and image posteriors, according to a paper by Chinese researchers.
The researchers came up with a framework to do just that. Dubbed DreamLLM, the framework enables models to generate raw images and text in an interleaved, auto-regressive manner during pretraining. This allows joint modeling of all multimodal distributions – in simple terms, DreamLLM is designed to make multimodal large language models more versatile and effective.
DreamLLM can be used to improve a multimodal model’s ability to generate content while following instructions – making it suitable to reduce manual effort in content creation by providing tailor-made multimodal outputs.
For example, a model utilizing DreamLLM could generate concepts for presentation slides that integrate both images and text. Or create large volumes of marketing content with customized images for different campaigns.
The researchers claim that it is the first multimodal large language model "capable of generating free-form interleaved content."
You can access DreamLLM on GitHub and use it commercially, with its license agreement granting freedom to distribute, modify and create derivative works of the model. Licensees must retain the DreamLLM attribution notice in distributed copies. However, if those wanting to use DreamLLM have over 700 million monthly active users, they need to request a separate commercial license from the DreamLLM authors.
The webpage for DreamLLM, which features several example generations, may look familiar to DreamFusion from Google since the Chinese researchers emulated the template.

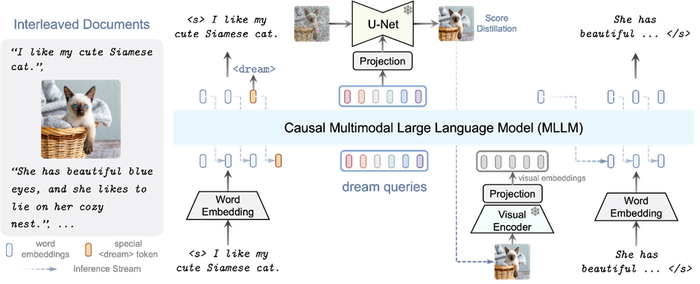
DreamLLM uses a technique the researchers call I-GPT (Interleaved Generative Pretraining) where a model is trained on documents with interleaved texts and images. The model learns multimodal representations by generating free-form interleaved documents during training – which the researchers suggest unlocks stronger comprehension and creation abilities.
Combining I-GPT, the researchers designed DreamLLM so it takes all raw data as inputs but also as outputs, a concept they call ‘dream queries.’
The paper explains how it works: "Interleaved documents serve as input, decoded to produce outputs. Both text and images are encoded into sequential, discrete token embeddings for the MLLM (multimodal LLM) input. A special <dream> token predicts where to generate images.
“Subsequently, a series of dream queries are fed into the MLLM, capturing holistic historical semantics. The images are synthesized by the SD image decoder conditioned on queried semantics. The synthesized images are then fed back into the MLLM for subsequent comprehension.”
Essentially, the model looks at the words and the pictures, understands what is going on and then generates something based on what is put in and the underlying context.
For a full breakdown, explore the DreamLLM paper, authored by researchers from Xi’an Jiaotong University, Tsinghua University, Huazhong University of Science and Technology and Chinese software developer MEGVII Technology.
Multimodality is increasingly becoming a focal point for the AI space, with OpenAI expanding ChatGPT with GPT-4V, allowing users to interact through image and voice inputs.
Meta has routinely touted multimodal AI models, with the likes of SeamlessM4T, AudioCraft and Voicebox designed to power its company-wide focus of creating metaverse experiences. Multimodal models are a focus of research for next-gen foundation models at the recently formed Frontier Model Forum – which is made up of major AI developers including OpenAI, Microsoft, Google and Anthropic.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)