

Keep up with the ever-evolving AI landscape
Unlock exclusive AI content by subscribing to our newsletter!!
The financial data giant used its vast trove of information to build BloombergGPT

Several companies are building large language models, but one of the most unusual has to be financial data and news giant Bloomberg L.P.
Bloomberg, founded by former New York major Mike Bloomberg as a financial data house with a quantitatively driven news division, has unveiled BloombergGPT. The language model is trained on a “wide range” of financial data to support a “diverse” set of NLP tasks in the industry, the company said.
The company said that while advances in large language models have demonstrated new applications, “the complexity and unique terminology of the financial domain warrant a domain-specific model.”
BloombergGPT will be used for financial NLP tasks such as sentiment analysis, named entity recognition, news classification and question-answering.
The model will also be used to introduce new ways of mining the vast troves of data on the Bloomberg Terminal, which for years has used function keys and a complex user interface.
Bloomberg CTO Shawn Edwards said in a blog that BloombergGPT will enable the company to tackle new types of applications faster, with “higher performance” at the get-go than creating custom models for each application.
A paper outlining the model can be found on arXiv.
In terms of size, BloombergGPT is made up of 50 billion parameters. To put that in perspective, OpenAI’s GPT-3, which recently was upstaged by GPT-4, is 175 billion parameters.
BloombergGPT is relatively small for an LLM, and nearest size comparison would be Meta’s 65 billion LLaMA model. However, the model is trained specifically for highly specific financial NLP tasks, meaning it would not need more general data like an OpenAI model.
The model was created by using Bloomberg’s extensive archive of financial data, with a 363 billion token dataset consisting of English financial documents augmented with a 345 billion token public dataset to create a large training corpus with over 700 billion tokens.
Bloomberg ML engineers then trained a 50-billion parameter decoder-only causal language model, with the resulting model validated on finance-specific NLP benchmarks, as well as a suite of internal standards.
In terms of popular NLP benchmarks like BIG-bench Hard and MMLU, Bloomberg said its model “outperforms existing open models of a similar size on financial tasks by large margins, while still performing on par or better on general NLP benchmarks.”
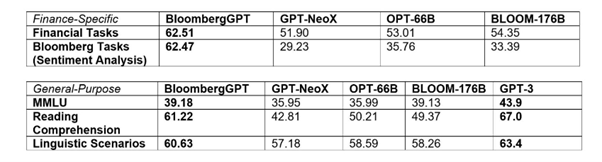
For finance-specific benchmarks, BloombergGPT was found to rival larger open source models, such as Bloom and OPT-66B. Bloomberg also scored better than smaller open source models such as Hugging Face’s GPT-NeoX.
In more general benchmark tests, BloombergGPT failed however to defeat OpenAI's GPT-3 but did achieve results that were not too far off.
OpenAI and Google are using their large language models to power new offerings for tasks like code generation and production workflow improvements.
But as interest in LLMs increases, so does the number of players developing their own iterations. Just last week, Cerebras, the chip-making startup, unveiled its own large language models trained on its AI supercomputer, Andromeda. And Salesforce created EinsteinGPT for customer relationship management.
The sheer costs that go into making these models can price a lot of businesses out from developing their own. But a few exceptions to this rule have arisen of late. AI researchers at Stanford unveiled Alpaca, a language model trained for just $600, although a problematic demo was taken down due to the model hallucinating. And reducing costs further, Databricks showcased the ChatGPT clone Dolly that was made for just $30.
But according to some big names in the world of tech, AI developments like these should stop altogether for six months to research their impact. The likes of Elon Musk and Apple cofounder Steve Wozniak signed an open letter calling for a pause on AI development. However, the idea was derided by some such as Turing award winner Yann LeCun.
Read more about:
ChatGPT / Generative AIYou May Also Like
.jpg?width=700&auto=webp&quality=80&disable=upscale)
.jpg?width=700&auto=webp&quality=80&disable=upscale)

.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)
.jpg?width=300&auto=webp&quality=80&disable=upscale)